What is FP-Growth (Frequent Pattern Growth)?
An effective and scalable technique for mining frequent itemsets in big transactional databases is the FP-Growth (Frequent Pattern Growth) algorithm. By employing a tree-based structure known as the FP-tree (Frequent Pattern Tree), FP-Growth eliminates the requirement for candidate generation and drastically lowers the number of database scans, in contrast to the Apriori method, which creates candidate itemsets and conducts several database scans. Key Characteristics are:
- Pattern-growth approach: It uses the FP-tree to iteratively construct frequent patterns.
- Compact representation: To save storage space and processing time, a compressed form of the database (FP-tree) is used.
- No candidate generation: This saves money by eliminating the need to create and evaluate every potential itemset.
Example Use Case: In market basket analysis, FP-Growth can efficiently discover item combinations frequently bought together (e.g., {milk, bread}).
Introduction of FP-Growth Algorithm
Jiawei Han et al. presented the FP-Growth algorithm, which stands for Frequent Pattern Growth, in 2000 as a more effective substitute for conventional frequent itemset mining methods such as the Apriori algorithm. Finding patterns, relationships, or correlations between groupings of objects in huge datasets is a common application of frequent pattern mining, a fundamental problem in data mining. The first significant algorithm for this task, Apriori, has performance problems since it generates expensive candidates and requires numerous database scans. To solve these inefficiencies, FP-Growth is used.
Key Concepts in FP-Growth:
- Frequent Pattern Tree (FP-tree): A condensed version of the transactional database that preserves information about itemset associations.
- Divide-and-conquer approach: By constructing conditional FP-trees for every item, FP-Growth breaks the problem down into smaller sub-problems.
- Header table: Facilitates effective access and pattern mining by maintaining track of items and their links inside the tree.
Only two complete database scans are needed, which greatly decreases time complexity by preventing the formation of duplicate candidates. It works especially well on dense and huge datasets. It Switching from a generate-and-test to a divide-and-conquer strategy, the FP-Growth algorithm transformed pattern mining and made it possible to find patterns in real-world data much more quickly and scalable.
Detailed of FP-Growth Algorithm
Without creating candidate itemsets, the FP-Growth algorithm locates frequently occurring itemsets in a transaction database. It accomplishes this by employing a recursive divide-and-conquer strategy with a small data structure known as an FP-tree (Frequent Pattern Tree). Step-by-Step Breakdown of the FP-Growth Algorithm:
Step 1: Scaz the Database and Count Item Frequencies
- Go through the dataset once to calculate the support count (frequency) of each item.
- Discard items that do not meet the minimum support threshold.
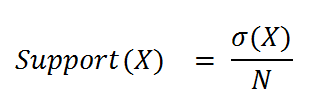
Where:
- σ(X) sigma = number of transactions containing itemset X
- N = total number of transactions
Step 2: Build the FP-Tree
- Sort frequent items in each transaction by descending support.
- Insert transactions into the FP-tree:
- Start with a null root.
- For each transaction, create a path in the tree using sorted frequent items.
- If a prefix already exists, increase the count of existing nodes.
- Use a header table to maintain pointers to all nodes with the same item label for easy access.
FP-Tree Structure Example:

Step 3: Mine Frequent Patterns from the FP-Tree
- Start from the Bottom of the Header Table: Pick the least frequent item (e.g., “Butter”) and find all paths leading to it (called conditional pattern base).
- Build Conditional FP-Trees: For each item, build a conditional FP-tree using its pattern base.
- Recursively Mine the Tree: Apply the FP-Growth algorithm recursively to each conditional FP-tree. For each frequent item, concatenate it with the suffix pattern to form complete frequent itemsets.
Example:
Assume the following simplified transactions:
| TID | Items |
| T1 | A, B, D |
| T2 | B, C, E |
| T3 | A, B, C, E |
| T4 | A, B, C, D |
| T5 | B, C |
Let’s say the minimum support count is 3.
- Frequent items (by support): B(5), C(4), A(3), D(2), E(2)
- Sorted frequent items: B, C, A
Build the FP-tree and then recursively mine it using conditional FP-trees of A, C, B.
Advantages of the Recursive Mining Process:
- Efficient memory use by compressing data into the FP-tree.
- No need to generate and test candidate sets, unlike Apriori.
- Recursive conditional mining enables deeper and more efficient pattern extraction.
Advantages and Disadvantages of FP-Growth Algorithm
Advantages
- Avoids Candidate Generation: Unlike Apriori, FP-Growth doesn’t generate candidate itemsets, which reduces computation time significantly.
- Efficient for Large Datasets: Particularly faster and more scalable than Apriori when dealing with large datasets or databases with long frequent patterns.
- Compact Data Representation (FP-Tree): Uses an FP-Tree to compress the dataset, which captures the frequency of itemsets in a compact structure, reducing memory usage.
- Fewer Database Scans: Only requires two full scans of the database (one for support count, another to build the FP-Tree), improving performance over Apriori.
- Good Performance with Dense Data: Especially effective for dense datasets where many items frequently co-occur.
- Recursive Pattern Growth: Uses divide-and-conquer strategy to explore conditional FP-trees, which is memory- and time-efficient.
Disadvantages
- Complex Tree Structure: FP-Tree can become very large and complex if the dataset has too many distinct items or low minimum support thresholds.
- Difficult to Implement: FP-Growth is algorithmically more complex to implement correctly compared to Apriori.
- Not Suitable for Incremental Updates: Once built, the FP-Tree cannot be easily updated with new transactions; you must rebuild the tree.
- Memory Overhead: While generally efficient, in worst-case scenarios (e.g., sparse data with low support threshold), the FP-Tree and its recursive structures can consume a lot of memory.
- Performance Degrades with Sparse Data: FP-Growth works best with dense datasets; in sparse datasets, the benefits of tree compression are diminished.
- Limited Interpretability: Understanding the structure of an FP-tree and how it represents frequent patterns can be non-trivial for beginners.
Comparing FP-Growth with Apriori:
| Feature | FP-Growth | Apriori |
| Candidate Generation | No | Yes |
| Database Scans | Two | Multiple |
| Memory Efficiency | High | Low |
| Performance on Large Data | Excellent | Poor |
| Uses Tree Structure | FP-Tree | No |
Applications of FP-Growth Algorithm
The FP-Growth algorithm is widely applied across various domains that involve large volumes of transactional or categorical data. Its ability to efficiently discover frequent itemsets without generating candidates makes it a valuable tool for uncovering hidden patterns, associations, and relationships in datasets. Below are some key application areas:
- Market Basket Analysis: FP-Growth is widely used in market basket analysis, which is a popular method for identifying products that are often bought together. Retailers utilize these findings to create recommendation systems, promotions, cross-selling, and product positioning tactics that work. Bundling decisions can be informed, for instance, by learning that customers who purchase bread and butter also regularly purchase jam.
- Mining Web Usage: When it comes to online analytics, FP-Growth assists in identifying recurring patterns in user movement paths, such as typical page sequences. This data is essential for providing customized content or ads, enhancing user experience, and optimizing website design.
- Recommendation Systems: By analyzing user activity patterns, FP-Growth can be used to produce tailored suggestions. Platforms can suggest goods, films, or services that are frequently linked to those chosen by comparable users by mining frequently occurring itemsets in user preferences or transaction histories.
- Bioinformatics and Healthcare: FP-Growth is used in bioinformatics to identify recurrent DNA or protein sequences and other patterns in genetic data. It supports better diagnosis and tailored treatments in the medical field by assisting in the analysis of patient records to find common symptom clusters or treatment combinations.
- Fraud Detection and Risk Management: FP-Growth is used by banks and other financial organizations to identify questionable trends in transaction data. Frequent occurrences of particular transaction types, places, or periods can be used as markers of risk or fraudulent activity, facilitating early discovery and response.
- Social Media and Text Mining: To find frequently occurring keywords, hashtags, or phrases, FP-Growth can also be used to analyze unstructured text or social media data. Better sentiment analysis, trend analysis, and content targeting are made possible by this.
In the FP-Growth algorithm is a strong and adaptable instrument with uses that go well beyond retail. It is perfect for contemporary data mining activities in a variety of industries, including digital marketing, e-commerce, banking, and healthcare, because to its effectiveness in managing enormous datasets.
Conclusion
One particularly effective and scalable technique for mining frequent itemsets in big datasets is the FP-Growth (Frequent Pattern Growth) algorithm. In contrast to more conventional algorithms like Apriori, FP-Growth does not require candidate creation, which greatly lowers computational cost and improves performance. FP-Growth provides a quicker and more memory-efficient method of pattern recognition by utilizing a small data structure known as the FP-tree and implementing a recursive divide-and-conquer strategy. It is especially useful in real-world applications ranging from fraud detection and genomics to market basket analysis and recommendation systems because of its capacity to manage huge, dense datasets. All things considered, FP-Growth has established itself as a fundamental algorithm in the data mining space, providing both theoretical beauty and real-world efficacy for revealing obscure patterns in transactional data.
Frequently Asked Questions (FAQs)
Q1. What makes FP-Growth faster than the Apriori algorithm?
Answer: Because it skips the expensive candidate generation step that Apriori uses, FP-Growth is quicker. In contrast to Apriori, which requires numerous database scans, it uses a compressed data structure (FP-tree) and mines frequent patterns straight from the tree.
Q2. What is an FP-tree, and why is it important?
Answer: A compact data structure called an FP-tree (Frequent Pattern Tree) uses shared prefixes to store transactional databases in a compressed format. It makes it possible to mine common patterns effectively without repeatedly scanning the original material.
Q3. When should I use FP-Growth over other frequent pattern mining algorithms?
Answer: Large, dense datasets with numerous frequent itemsets are best suited for FP-Growth. FP-Growth is typically the recommended approach when memory and performance efficiency are crucial and candidate generation is too expensive.
Q4. Are there any limitations to the FP-Growth algorithm?
Answer: FP-Growth is effective, however for very big and sparse datasets, mining conditional trees and constructing the FP-tree might be memory-intensive. When the tree has a lot of branches with little overlap, it could also get complicated.
Q5. Can FP-Growth be used for association rule mining?
Answer: Indeed, common itemsets are found using FP-Growth and serve as the foundation for the creation of association rules. Meaningful rules can be extracted by using lift and confidence measures after frequent itemsets have been identified.