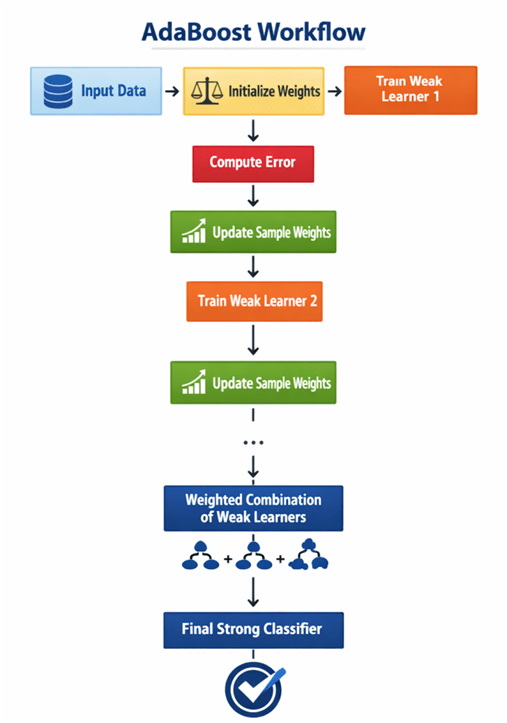
What is AdaBoost Algorithm?
AdaBoost, short for Adaptive Boosting, is one of the earliest and most influential ensemble learning algorithms in machine learning. It was introduced by Yoav Freund and Robert Schapire in 1996 as a practical implementation of boosting theory. At its core, AdaBoost is an ensemble learning method that combines multiple weak learners to create a strong classifier. A weak learner is a model that performs only slightly better than random guessing (for binary classification, better than 50% accuracy). AdaBoost builds a strong predictive model by training these weak learners sequentially, with each new learner focusing more on the instances that previous learners misclassified. The algorithm is primarily used for classification problems, although extensions such as AdaBoost.R2 allow it to be applied to regression tasks.
The key idea behind AdaBoost is simple yet powerful:
- Assign equal weights to all training samples initially.
- Train a weak learner.
- Increase the weights of misclassified samples.
- Train the next weak learner using the updated weights.
- Combine all weak learners into a weighted majority vote.
Adaptively adjusts weights based on previous errors, AdaBoost “learns from its mistakes” — hence the name Adaptive Boosting.
Introduction of AdaBoost Algorithm
AdaBoost belongs to the family of boosting algorithms, a subcategory of ensemble methods. Unlike bagging methods such as Random Forest, which train models independently in parallel, boosting methods train models sequentially, where each new model corrects the errors of the previous one. The theoretical foundation of AdaBoost lies in boosting theory, which demonstrates that multiple weak learners can be combined to produce a strong learner with arbitrarily low training error. AdaBoost emerged from theoretical research in computational learning theory. The collaboration between Freund and Schapire led to a practical algorithm that worked remarkably well in real-world scenarios. AdaBoost gained widespread popularity after its successful use in face detection by Paul Viola and Michael Jones in the famous Viola-Jones object detection framework.
Why AdaBoost is Important?
- Converts weak learners into strong ones
- Automatically adjusts sample weights
- Simple implementation
- Strong theoretical guarantees
- Performs well in many real-world applications
Detailed AdaBoost Algorithm
Let us consider a binary classification problem:
Training dataset:
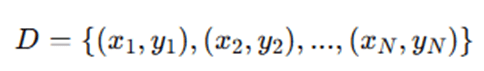
Where:
- xi∈Rd
- yi∈{−1,+1}
Let the number of boosting rounds be T.
Step 1: Initialize Sample Weights
Assign equal weight to each training sample:
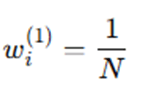
Where:
- wi(1) = weight of sample i at iteration 1
- N = total number of training samples
Step 2: Train Weak Learner
For each boosting iteration t=1,2,…,Ts:
Train a weak learner ht(x) using weights wi(t).
Step 3: Compute Weighted Error
Calculate weighted error of classifier ht:
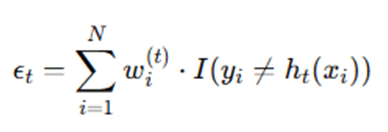
Where:
- I(⋅) is indicator function:
- 1 if condition true
- 0 otherwise
Step 4: Compute Classifier Weight
Compute the importance weight of the weak learner:
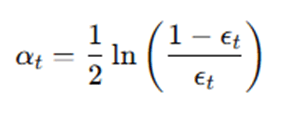
This determines how much influence the classifier has in the final model.
Step 5: Update Sample Weights
Update weights:
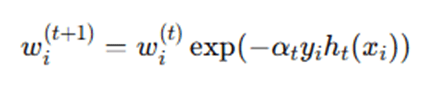
If sample correctly classified:
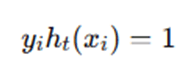
If misclassified:
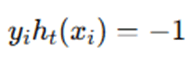
Thus:
- Correct → weight decreases
- Incorrect → weight increases
Step 6: Normalize Weights
Normalize to ensure they sum to 1:
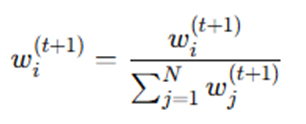
Step 7: Final Strong Classifier
After T iterations:

The final prediction is a weighted majority vote.
AdaBoost begins by assigning equal importance to every data point in the training dataset. This ensures that the algorithm starts without bias toward any particular instance. The model then trains the first weak learner—commonly a decision stump (a one-level decision tree). Because all samples have equal weight, the learner tries to minimize classification error across the entire dataset. After training the first weak learner, AdaBoost evaluates its performance by calculating the weighted error rate. If the classifier performs poorly (error > 0.5), it is discarded. Otherwise, the algorithm computes the classifier’s weight using a logarithmic formula that reflects its accuracy. The better the classifier performs, the higher its influence in the final ensemble. Next, AdaBoost adjusts the weights of training samples. Misclassified samples receive higher weights, meaning the next weak learner will focus more heavily on these difficult examples. Correctly classified samples receive reduced weights. This reweighting process is what makes AdaBoost adaptive. The weights are then normalized to ensure they form a probability distribution. This process repeats for a predefined number of iterations. Each iteration produces a weak classifier and its corresponding weight.
AdaBoost constructs the strong classifier by combining all weak learners through a weighted vote. Each learner contributes proportionally to its accuracy. The final prediction is determined by the sign of the weighted sum of predictions. This iterative focus on difficult cases allows AdaBoost to progressively improve classification performance and reduce bias.
Example: How AdaBoost Works
Let’s consider a simple binary classification problem:
We have 10 samples:
- 5 positive (+1)
- 5 negative (-1)
Iteration 1:
- Equal weights = 0.1
- Weak learner misclassifies 3 samples
- Error = 0.3
- Compute alpha
- Increase weights of 3 misclassified samples
Iteration 2:
- New learner focuses on difficult samples
- Misclassifies 2 samples
- Error = 0.2
- Compute alpha
- Update weights again
Iteration 3:
- Focus shifts further
- Ensemble formed
Final Prediction:
Weighted majority vote determines class.
Advantages and Disadvantages of AdaBoost
Advantages
- Simple to Implement: AdaBoost is conceptually straightforward and easy to implement. It mainly requires a weak learner (often a decision stump) and a mechanism to update sample weights iteratively.
- Strong Theoretical Foundation: AdaBoost is backed by solid mathematical theory. It minimizes exponential loss and has proven guarantees that training error decreases as more weak learners are added (under certain conditions).
- Works Well with Weak Learners: One of AdaBoost’s greatest strengths is its ability to convert weak learners—models performing slightly better than random guessing—into a strong classifier through weighted combination.
- Less Prone to Overfitting (with Proper Tuning): In many practical cases, AdaBoost shows good generalization performance and is less likely to overfit compared to complex standalone models, especially when the number of boosting rounds is properly controlled.
- Minimal Parameter Tuning: Unlike many advanced ensemble methods, AdaBoost requires relatively few hyperparameters, mainly the number of estimators and the learning rate, making it easier to tune.
- Adaptive to Misclassified Samples: AdaBoost automatically increases the importance of misclassified samples, allowing the model to focus on hard-to-classify data points in subsequent iterations.
Disadvantages
- Sensitive to Noisy Data: Because AdaBoost increases weights for misclassified samples, noisy data points may receive excessive attention, which can degrade performance.
- Sensitive to Outliers: Outliers are often repeatedly misclassified, causing their weights to grow significantly and potentially dominating the training process.
- Overemphasis on Difficult Samples: The algorithm may focus too much on a small number of hard examples, reducing overall robustness if those samples are not representative.
- Sequential Training Process: AdaBoost trains weak learners sequentially, meaning each learner depends on the previous one. This makes it less suitable for parallel processing compared to bagging methods.
- Requires Careful Weak Learner Selection: The performance of AdaBoost depends heavily on the choice of weak learners. Very complex base models can lead to overfitting, while overly simplistic models may not capture meaningful patterns.
Applications of AdaBoost Algorithm
AdaBoost has demonstrated strong performance across various real-world domains due to its ability to enhance weak learners and iteratively focus on difficult samples. Below are the key application areas summarized with subheadings.
- Face Detection: AdaBoost gained major recognition through the Viola–Jones object detection framework, developed by Paul Viola and Michael Jones. In face detection systems, it selects the most discriminative Haar-like features from thousands of possibilities and combines weak classifiers into a strong real-time face detector. This made accurate face detection possible even on low-power devices.
- Text Classification: In Natural Language Processing (NLP), AdaBoost is widely used for spam detection, sentiment analysis, topic classification, and fake news detection. By increasing the weights of misclassified text samples, the algorithm improves performance in high-dimensional feature spaces such as TF-IDF representations.
- Medical Diagnosis: AdaBoost supports disease classification tasks such as cancer detection, diabetes prediction, and heart disease diagnosis. It enhances predictive accuracy by focusing on difficult patient cases. Its interpretability (with simple weak learners) also makes it suitable for healthcare environments where explainability is essential.
- Credit Risk Assessment: In financial institutions, AdaBoost is applied to loan default prediction, credit scoring, and risk classification. By combining multiple weak models trained on financial attributes, it improves the identification of high-risk borrowers, particularly in imbalanced datasets.
- Fraud Detection: AdaBoost is widely used in banking and e-commerce fraud detection systems. It helps detect rare fraudulent transactions—such as credit card fraud and insurance claim fraud—by assigning higher importance to misclassified fraud cases and improving anomaly detection.
- Object Detection: Beyond face detection, AdaBoost is used in pedestrian detection, vehicle recognition, and traffic sign identification. It selects discriminative visual features and aggregates weak classifiers into strong detection models, especially in lightweight or resource-constrained applications.
- Bioinformatics: In genomics and bioinformatics, AdaBoost is applied to gene expression classification, protein function prediction, and cancer subtype identification. It effectively handles high-dimensional biological datasets by improving classification robustness through iterative reweighting.
AdaBoost has been successfully applied in computer vision, NLP, healthcare analytics, financial modeling, cybersecurity, and bioinformatics. Although advanced boosting methods and deep learning models are now more dominant, AdaBoost remains a foundational and versatile ensemble learning algorithm.
Conclusion
AdaBoost stands as one of the most foundational and influential ensemble learning algorithms in the history of machine learning. Introduced by Yoav Freund and Robert Schapire, the algorithm transformed the theoretical concept of boosting into a practical and highly effective learning framework. Its core strength lies in its adaptive mechanism—sequentially training weak learners while dynamically adjusting sample weights to emphasize previously misclassified instances. Through this iterative correction process, AdaBoost converts multiple weak classifiers into a strong and highly accurate predictive model. One of the defining characteristics of AdaBoost is its mathematical elegance. The algorithm minimizes exponential loss and provides theoretical guarantees that training error decreases as additional weak learners are added (assuming each performs better than random guessing). This property gives AdaBoost a solid theoretical foundation, distinguishing it from many heuristic-based machine learning methods. In practice, AdaBoost has demonstrated strong performance across domains such as computer vision, text classification, healthcare analytics, financial risk modeling, and fraud detection. Its success in early real-time face detection systems, particularly within the Viola–Jones object detection framework, highlighted its practical impact and scalability.
Although more advanced boosting techniques such as Gradient Boosting and XGBoost have since emerged—offering improved performance, better regularization, and enhanced scalability—AdaBoost remains conceptually significant. It serves as the foundation for understanding boosting principles, including sequential learning, weighted model aggregation, and error-driven optimization.
Frequently Asked Questions (FAQs)
1. Is AdaBoost only for classification?
Primarily, AdaBoost is designed for binary classification tasks. However, extensions such as AdaBoost.R2 adapt the framework for regression problems by modifying the loss function and weight update rules. Multi-class classification variants like SAMME also extend its capabilities beyond binary settings.
2. What type of weak learners are commonly used?
The most commonly used weak learners in AdaBoost are decision stumps (one-level decision trees). These simple models are computationally efficient and typically perform slightly better than random guessing, making them ideal candidates for boosting. However, other base learners such as shallow decision trees or simple linear classifiers can also be used depending on the problem.
3. Why is AdaBoost sensitive to noise?
AdaBoost increases the weights of misclassified samples at each iteration. If the dataset contains noisy observations or mislabeled instances, these points may repeatedly be misclassified. As a result, their weights grow significantly, causing the algorithm to focus excessively on noise rather than meaningful patterns, which can reduce generalization performance.
4. What is the main difference between AdaBoost and Gradient Boosting?
The primary difference lies in how errors are handled. AdaBoost adjusts sample weights to emphasize misclassified observations and combines weak learners using weighted voting. In contrast, Gradient Boosting sequentially fits new models to the residual errors of previous models using gradient descent optimization. While AdaBoost minimizes exponential loss, Gradient Boosting can optimize various differentiable loss functions, making it more flexible.
5. Can AdaBoost overfit?
Yes, although AdaBoost often demonstrates strong generalization performance, it can overfit under certain conditions—especially when the dataset contains significant noise, outliers, or when too many boosting rounds are used. Proper tuning of the number of estimators and learning rate is essential to balance bias and variance.