What is Apriori Algorithm?
Large transactional databases can be mined for frequent itemsets and association rules using the traditional Apriori approach. Finding patterns of items that commonly co-occur in transactions is the main purpose of market basket analysis. The Apriori property says, “If an itemset is frequent, then all of its subsets must also be frequent.” This is the basis upon which the algorithm works. This characteristic aids the algorithm in narrowing down the search space, increasing the effectiveness of finding recurring patterns. Key Concepts are:
- Frequent Itemsets: Sets of items that appear together in a transactional database with frequency above a specified threshold (called support).
- Association Rules: These are implication rules of the type A → B, which state that B is likely to occur when A does. Metrics of confidence and support are used to assess these.
In association rule mining, apriori is fundamental and a precursor to more complex algorithms such as FP-Growth.
Introduction of Apriori Algorithm
Rakesh Agrawal and Ramakrishnan Srikant developed the Apriori algorithm in 1994 to find association rules in big datasets and mine frequent itemsets effectively. It was among the first algorithms created for learning association rules and is now a key strategy in market analysis and data mining. The Goal is: Finding hidden patterns, correlations, or links among a collection of entries in transactional databases is the primary objective of the Apriori algorithm. For instance, it assists companies in determining which goods are frequently purchased in tandem, allowing them to maximize marketing, inventory, and promotions. Working Principle of are Apriori algorithm:
- Iterative (level-wise) approach: It generates candidate itemsets of increasing length (1-itemsets, 2-itemsets, etc.).
- Support-based pruning: It removes candidate itemsets that don’t satisfy a minimal support level at every stage.
- The apriori property: It guarantees computing efficiency by eliminating itemsets before any of their subgroups are rare.
Use Case Example:
In a grocery store, Apriori can help determine that:
“Customers who buy bread and butter are likely to also buy jam.”
Such insights enable cross-selling, store layout optimization, and personalized recommendations.
In Apriori is a foundational algorithm in data science that paved the way for intelligent decision-making through pattern discovery in large datasets.
Detailed Apriori Algorithm
The Apriori algorithm works in an iterative manner to discover frequent itemsets and generate association rules based on user-defined thresholds for support and confidence. Step-by-Step Process of the Apriori Algorithm as below,
Step 1: Define Key Parameters
- Minimum Support (min_sup): The minimum proportion of transactions that an itemset must appear in to be considered frequent.
- Minimum Confidence (min_conf): The minimum strength of implication for a rule to be accepted.
Step 2: Generate Frequent 1-itemsets (L1)
- Scan the entire transaction database.
- Count the frequency of each individual item.
- Retain only those items that satisfy the minimum support threshold.
Support Formula are,

Step 3: Generate Candidate 2-itemsets (C2)
- Form candidate 2-itemsets by self-joining the frequent 1-itemsets.
- Apply Apriori property: If any subset of a candidate is not frequent, discard it.
Step 4: Count Support for C2 and Generate L2
- Scan the database and calculate support for each candidate in C2.
- Prune candidates that do not meet minimum support → this becomes L2 (frequent 2-itemsets).
Repeat steps 3 and 4 for k-itemsets (Ck → Lk), increasing k by 1 in each iteration until no more frequent itemsets can be found.
Step 5: Generate Association Rules
For each frequent itemset L, generate all possible non-empty subsets. For each rule of the form A→B, calculate:
- Confidence:
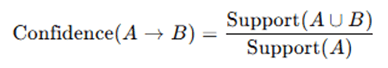
- Lift (optional but common):

Accept rules that meet min_confidence.
Repeat Until Completion
- Stop when no further frequent itemsets can be generated (i.e., the candidate set becomes empty).
Illustrative Example , Suppose you have 5 transactions:
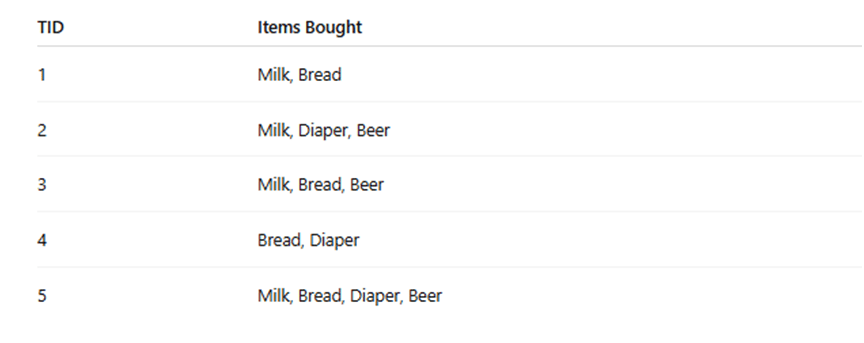
- min_support = 0.6
- min_confidence = 0.8
You’d find:
- L1: {Milk}, {Bread}, {Beer}, {Diaper}
- L2: {Milk, Bread}, {Milk, Beer}, etc.
- Then evaluate rules like {Milk} → {Bread} with calculated confidence.
Advantages and Disadvantages of Apriori Algorithm
Advantages
- Simple and Intuitive: The Apriori algorithm is easy to understand and implement. Its logic is based on the Apriori property: if an itemset is frequent, all its subsets must also be frequent. This makes the algorithm conceptually straightforward and suitable for educational purposes or initial data exploration.
- Effectiveness for Small Datasets: Apriori performs well on small and moderately sized datasets where the number of items and transactions is not excessively large. It can generate useful and interpretable association rules in such contexts.
- Works Without Complex Data Structures: Unlike some advanced algorithms (like FP-Growth), Apriori does not require specialized data structures like trees. It relies on basic operations like set intersection and counting, making it suitable for environments with limited resources or simple data pipelines.
- Generates All Frequent Itemsets: Apriori guarantees the discovery of all frequent itemsets above the user-specified support threshold. It is exhaustive and ensures that no valid rule is missed, which is critical in certain applications like medical or legal data analysis.
- Customizable Support and Confidence: Users can specify minimum support and confidence thresholds, giving flexibility to control the granularity and quality of the rules discovered. This allows fine-tuning to suit specific application needs.
Disadvantages
- High Computational Cost: Apriori suffers from combinatorial explosion as the number of items increases. It generates a large number of candidate itemsets, especially when the dataset has low support thresholds, which results in high computational and memory requirements.
- Multiple Database Scans: The algorithm requires multiple full scans of the database — once for each level of itemsets (e.g., 1-itemset, 2-itemset, etc.). This makes it inefficient on large datasets, where repeated disk I/O operations become costly.
- Generates Many Redundant Rules: Apriori often produces a large number of association rules, many of which may be redundant or irrelevant. This can make it difficult to interpret the results or to identify the truly meaningful patterns.
- Poor Scalability: Due to its resource-intensive nature, Apriori does not scale well to large datasets or datasets with a high number of items. It may become impractical for real-world applications involving millions of transactions.
- Assumes Binary Attributes: Apriori is best suited for transactional data with binary (present/absent) items. It struggles with continuous or multi-valued attributes unless preprocessing (e.g., binning or discretization) is applied.
| Aspect | Advantage | Disadvantage |
| Simplicity | Easy to understand and implement | Lacks optimization for performance |
| Dataset Suitability | Good for small/medium datasets | Not suitable for large-scale or high-dimensional data |
| Completeness | Finds all frequent itemsets | May produce too many (including irrelevant) rules |
| Efficiency | No need for complex data structures | Multiple database scans; high computational cost |
| Flexibility | Allows custom support/confidence thresholds | Requires binary/categorical data only |
Applications of Apriori Algorithm
The Apriori algorithm plays a critical role in uncovering hidden associations and patterns within large datasets, making it a valuable tool across multiple industries. Its strength lies in identifying frequent itemsets and generating association rules that can inform decision-making, enhance user experiences, and drive business insights. Below are some of the most impactful applications of Apriori in various fields.
- Market Basket Analysis: One of the most common applications of the Apriori algorithm is in market basket analysis, where retailers analyze customer purchasing patterns to identify items that are frequently bought together. For example, analysis might reveal that customers who buy bread and butter often also purchase jam. Such insights allow businesses to strategically place related products near each other in stores, create bundled product offerings, or implement targeted promotions and combo discounts. As a result, businesses can improve sales, optimize store layout, and enhance customer satisfaction by catering to shopping habits.
- Web Usage Mining: In the realm of digital marketing and website optimization, Apriori is applied to web usage mining. This involves analyzing user clickstream data to understand navigation behavior on a website. For instance, the algorithm may uncover that users who visit the homepage and then the pricing page often proceed to the signup page. By understanding these patterns, website designers and marketers can restructure web navigation to guide users more effectively, leading to improved user engagement, higher conversion rates, and an optimized overall experience.
- Medical Diagnosis and Healthcare: Apriori also finds significant application in medical diagnosis and healthcare analytics, where it helps uncover co-occurring symptoms, treatments, or diagnoses. For example, it may reveal that patients with high blood pressure and high cholesterol frequently also suffer from diabetes. These insights can support doctors in forming more accurate diagnoses, developing preventive care plans, and discovering potential interactions between treatments. Furthermore, healthcare providers can enhance personalized medicine and patient care strategies by leveraging these associations.
- Fraud Detection: In fraud detection, Apriori helps financial institutions identify unusual transaction patterns that may indicate fraudulent activity. For example, if a certain set of transactions typically occurs together and an unexpected deviation is detected, this anomaly can be flagged as suspicious. Such patterns are particularly useful in identifying credit card fraud, insurance scams, or money laundering activities. By continuously learning from transaction histories, Apriori can strengthen security protocols and contribute to more robust financial monitoring systems.
- Recommendation Systems: Recommendation engines benefit from Apriori by leveraging user behavior data to suggest relevant products or content. In e-commerce platforms, for example, if a user purchases a smartphone, the algorithm can recommend phone cases, chargers, or screen protectors based on common buying patterns. These data-driven suggestions help personalize the user experience, increase cross-selling opportunities, and boost customer satisfaction and loyalty.
- Bioinformatics and Genomics: In the field of bioinformatics, Apriori is used to analyze complex biological data such as gene expression patterns. It can discover associations between specific genes and medical conditions, such as identifying that gene A and gene B frequently appear together in patients suffering from a particular disease. These findings can assist researchers in understanding genetic influences on disease development, contribute to drug discovery, and guide future medical research efforts by illuminating hidden biological relationships.
Conclusion
In data mining, the Apriori algorithm is still a fundamental method, especially when it comes to finding frequently occurring itemsets and producing association rules in sizable datasets. Its simplicity and the Apriori property’s logical reasoning, which allow for efficient search space reduction and lower processing cost in many real-world situations, are its main advantages. Apriori is still frequently used for educational purposes, exploratory data analysis, and domains where interpretability and completeness are crucial, even if it is not as scalable as more sophisticated algorithms like FP-Growth. Applications in a variety of industries, including retail, healthcare, online analytics, and finance, show off its adaptability and usefulness in revealing latent patterns that can inform strategic choices. In conclusion, Apriori’s conceptual clarity, correctness, and wide applicability guarantee its continued significance in data science and machine learning, even though it might not be the most effective option for large datasets.
Frequently Asked Questions (FAQs)
Q1: What is the main purpose of the Apriori algorithm?
Answer: The Apriori algorithm is intended to help reveal patterns, such as which things are frequently purchased together, by identifying frequently occurring itemsets and producing meaningful association rules from transactional data.
Q2: What are the key metrics used in Apriori?
Answer: The two main metrics are confidence (the likelihood that item B will be bought when item A is bought) and support (the frequency with which an itemset occurs in the dataset). Lift can also occasionally be employed to gauge a rule’s strength beyond chance.
Q3: Why is it called “Apriori”?
Answer: The Apriori property, which holds that every subset of a frequent itemset must likewise be frequent, is the source of the name. This “prior” information aids in narrowing the search area.
Q4: What are the limitations of the Apriori algorithm?
Answer: Because of the numerous database scans and the numerous candidate itemsets that are produced, it might be computationally costly and is hence less appropriate for very big datasets.
Q5: How is Apriori different from FP-Growth?
Answer: FP-Growth mines frequent patterns without candidate generation using a tree-based structure, which makes it faster and more effective for huge datasets than Apriori, which employs a generate-and-test method with candidate itemsets and numerous database scans.