
What is Generative Adversarial Networks (GANs)?
Ian Goodfellow invented Generative Adversarial Networks (GANs) in 2014 as a kind of machine learning technique for generative modeling. Their main purpose is to create fresh data samples that closely mimic an existing dataset. Two neural networks make up a GAN:
- Generator (G): Uses random noise to create synthetic, or fake, data.
- Discriminator (D): Evaluates data and distinguishes between true data (from the dataset) and bogus data (generated by the generator).
In a game-theoretic setting, these two models are trained simultaneously: By creating realistic data, the Generator attempts to deceive the Discriminator. The discriminator makes an effort to accurately determine if the data is authentic or fraudulent. Both models get better over time: The Discriminator gets better at identifying phony data, and the Generator gets better at creating actual data.
The objective is to get to the point when the Generator has successfully learnt the actual data distribution, as indicated by the Discriminator’s inability to discriminate between created and real data. In fields including image synthesis, style transfer, data augmentation, and deepfake production, GANs are extensively utilized.
Introduction of Generative Adversarial Networks
In the realm of unsupervised machine learning, Generative Adversarial Networks (GANs) are a potent and inventive method that is mostly concerned with data production. Since its 2014 introduction by Ian Goodfellow and associates, GANs have emerged as a key method for creating incredibly lifelike synthetic data.
At their core, GANs consist of two neural networks:
- Generator (G): Takes random noise as input and learns to produce data that closely resembles real-world data.
- Discriminator (D): Receives both real data and fake data generated by the Generator, and learns to distinguish between the two.
These networks are trained in a minimax adversarial environment, in which the Discriminator improves its ability to identify phony data while the Generator keeps trying to generate increasingly realistic data to trick the Discriminator. As a result of this adversarial process, both models get better together, creating a generator that can generate data that is identical to real-world examples.
Reaching a Nash equilibrium, when the Generator generates data so realistic that the Discriminator has a 50% accuracy—that is, it can no longer reliably distinguish genuine from fake—is the training goal. GANs have revolutionized numerous fields, allowing significant breakthroughs like: Producing photorealistic, high-resolution photos, converting sketches to colored images, for example; improving image quality by using super-resolution; and producing training data for models in situations when real data is sensitive or hard to come by. GANs are among the most significant advancements in deep learning because of their straightforward structure and intricate training, which have spurred a great deal of research and innumerable real-world uses.
Detailed Generative Adversarial Networks (GANs)
The Generator (G) and Discriminator (D) engage in a two-player minimax game to operate Generative Adversarial Networks (GANs). A thorough description of the GANs algorithm, including each step and related formulas, can be found below. Components of GANs are,
1. Generator (G):
- Learns to map a random noise vector z (from a known distribution like Gaussian or Uniform) to the data space.
- Output: Fake data G(z) that mimics the real data.
2. Discriminator (D):
- A binary classifier that receives real data x and fake data G(z).
- Tries to correctly classify real vs. fake.
3.2. Objective Function
GANs use the following minimax objective function:
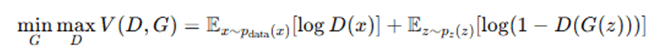
- D(x): Probability that x is real.
- G(z)): Generator’s output (fake data).
- pdata(x): Real data distribution.
- pz(z): Noise distribution (e.g., Normal or Uniform).
Training Procedure
Step-by-step GAN Algorithm:
Step 1: Initialize
- Randomly initialize parameters θG and θD for Generator and Discriminator.
- Choose a prior noise distribution pz(z) (e.g., standard normal distribution).
Step 2: Repeat for Each Training Iteration
1. Discriminator Update:
Sample real data
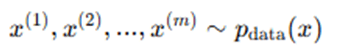
Sample noise vectors

Generate fake data
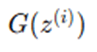
- Compute Discriminator Loss:
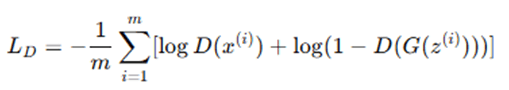
- Update Discriminator parameters θD using gradient descent:
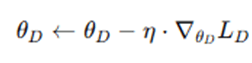
2. Generator Update:
Sample new noise vectors

Generate fake data
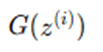
- Compute Generator Loss (using either):
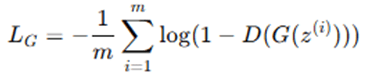
Modified (non-saturating) version – commonly used for better gradients:
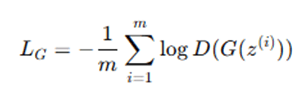
- Update Generator parameters θG using gradient descent:
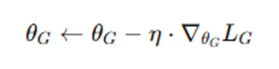
Step 3: Repeat Until Convergence
- Continue alternating updates to Discriminator and Generator until the Generator produces high-quality outputs indistinguishable from real data.
Optional Variants and Improvements,
- Conditional GANs (cGAN): Adds label information to guide generation.
- Wasserstein GAN (WGAN): Replaces the original loss with Earth Mover’s distance for more stable training.
- CycleGAN, StyleGAN, DCGAN: Architectural or conceptual improvements for specific applications.
This adversarial training paradigm leads to a Generator that captures the true data distribution, allowing it to generate high-quality, realistic synthetic data.
Advantages and Disadvantages of Generative Adversarial Networks (GANs)
Advantages
- High-Quality Data Generation: GANs are capable of generating extremely realistic and high-quality synthetic data, particularly in the domains of image, video, and audio generation. They outperform many other generative models like Variational Autoencoders (VAEs) when it comes to visual fidelity.
- Unsupervised Learning: GANs learn from unlabeled data, which is particularly useful when labeled datasets are scarce or expensive to produce. This makes them highly effective in unsupervised or semi-supervised learning settings.
- Versatile Applications: GANs are highly versatile and have been successfully applied to a wide range of tasks, including: Image synthesis (e.g., generating human faces), Style transfer (e.g., turning sketches into photos), Super-resolution (upscaling low-resolution images), Text-to-image generation, Data augmentation for imbalanced datasets
- Continuous Improvement During Training: The adversarial nature of GANs, where the generator and discriminator compete, drives continuous improvement. The generator learns to produce better data as the discriminator becomes more adept at detecting fake data.
- Implicit Density Estimation: Unlike other models that explicitly estimate probability distributions, GANs use implicit modeling. This allows them to bypass assumptions about data distribution and generate samples directly from the learned latent space.
- Creative Content Generation: GANs are widely used in art, music, and design for creating novel and diverse content, helping artists and developers experiment with new ideas and forms.
Disadvantages
- Training Instability: GANs are notoriously difficult to train due to their adversarial setup. The model may fail to converge, oscillate, or suffer from vanishing gradients, especially if the discriminator becomes too strong too quickly.
- Mode Collapse: A common issue in GAN training is mode collapse, where the generator produces a limited variety of outputs, essentially “fooling” the discriminator with the same type of data and ignoring diversity in the dataset.
- Requires Careful Tuning: GANs are highly sensitive to hyperparameters, model architecture, and training techniques. Successful training often requires extensive experimentation and tuning, making it time-consuming.
- Evaluation is Difficult: Evaluating the quality of generated samples is non-trivial and subjective. Metrics like Inception Score (IS) and Fréchet Inception Distance (FID) are used but don’t always correlate well with human judgment.
- No Explicit Likelihood: Unlike VAEs or autoregressive models, GANs do not offer a way to compute likelihoods or probabilities of generated data, making them unsuitable for tasks requiring probabilistic interpretation.
- Data Hunger: GANs require large amounts of data to generate high-quality outputs. With limited data, the generator may overfit or fail to generalize.
- Bias Amplification: GANs may unintentionally learn and replicate biases present in the training data, especially in sensitive applications like facial generation or synthetic media creation.
| Aspect | Advantages | Disadvantages |
| Output Quality | Generates high-fidelity data | May collapse to low-diversity outputs (mode collapse) |
| Learning Style | Works without labeled data | Requires a lot of unlabeled data to train effectively |
| Training Dynamics | Adversarial training improves generation quality | Prone to instability and convergence issues |
| Application Range | Very flexible (image, video, audio, text) | Evaluation of results is difficult and often subjective |
| Model Assumptions | No need to model explicit data distribution | Cannot compute likelihood or uncertainty |
| Usability | Can generate new, creative, diverse content | Requires careful architectural and hyperparameter tuning |
| Ethical Risks | Useful in creative domains | Can produce deepfakes or biased outputs |
Applications of Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) have found widespread application across multiple domains due to their ability to generate realistic, high-quality synthetic data. Below are key areas where GANs are making a significant impact:
- Image Generation: Generating realistic human faces by face synthesis (e.g., ThisPersonDoesNotExist.com). Art creation: paintings and artwork produced by AI that mimics the styles of well-known artists. Creating synthetic datasets involves creating images for training data, particularly in domains with a shortage of data.
- Image-to-Image Translation: Transferring an image’s artistic style to another image is known as style transfer. Colorization is the process of turning black-and-white pictures into colored ones. Super-resolution: Improving low-resolution photos’ quality and resolution. Conversions from day to night and from summer to winter: Used in autonomous driving to replicate various environments.
- Face swapping and deepfakes: producing incredibly lifelike videos in which one person’s face is replaced with another. utilized for visual effects in films, but it also presents security and ethical issues.
- Creating artificial : MRI, CT, or X-ray scans to train diagnostic models is known as medical imaging. improving scan noise reduction and image clarity. data augmentation when patient data is scarce.
- Audio and Speech Synthesis: Producing music and sounds that resemble those of humans. converting one voice into another or producing deepfake audio. improving audio recordings of poor quality.
- Data Augmentation: Adding realistic synthetic instances to limited datasets. beneficial in domains where gathering data is costly or challenging, such as robots.
- Genomics and Drug Discovery: Creating novel molecular structures with desirable characteristics. modeling biological facts in order to do research.
- Virtual reality and game development: producing lifelike landscapes, characters, and textures. making VR and AR applications more realistic.
- Anomaly Detection: When the Generator is unable to replicate specific patterns, anomalies are identified. This process trains GANs to learn the normal distribution of data.
Conclusion
Through providing a fresh and efficient method of generative modeling, Generative Adversarial Networks (GANs) have completely transformed the field of machine learning. Two neural networks, a Generator and a Discriminator, are trained adversarially to create extremely realistic synthetic data that closely resembles distributions found in the real world. They are especially useful in situations when data labeling is expensive or impractical because of their capacity to learn from unlabeled data. In a variety of applications, such as image synthesis, data augmentation, video production, and medical imaging, GANs have shown remarkable results. The ongoing development of GAN designs and methodologies, such as Conditional GANs, StyleGANs, and Wasserstein GANs, has greatly enhanced their performance and robustness, despite certain difficulties with training stability and evaluation. GANs are a key component of contemporary deep learning and are anticipated to become increasingly more important as research advances in the fields of science, the creative industries, and practical AI applications.
Frequently Asked Questions (FAQs)
Q1. What makes GANs different from other generative models?
Answer: Unlike techniques like Variational Autoencoders (VAEs), GANs generate highly realistic outputs without the need for an explicit probability model by using an adversarial training process that involves two networks (Generator and Discriminator).
Q2. Why are GANs difficult to train?
Answer: Because the training process is adversarial, GANs may exhibit instability. Finding a proper balance between the Generator and Discriminator is difficult because of issues including mode collapse, non-convergence, and vanishing gradients.
Q3. What is mode collapse in GANs?
Answer: Mode collapse occurs when the generator fails to fully capture the diversity of the data distribution by producing a small number of outputs (such as the same image again). It occurs when the Generator discovers a small number of samples that regularly deceive the Discriminator.
Q4. Can GANs be used for text or language generation?
Answer: Because language is distinct, using GANs for text generation is more difficult than using them for image and audio jobs. SeqGAN and TextGAN are two sophisticated architectures that try to close this gap.
Q5. Are GANs used in real-world commercial products?
Answer: Indeed, GANs are employed in many real-world applications, such as medical imaging upgrades, video game asset creation, photo editing tools, and artificial data for AI model training.









