
What is Naïve Bayes Algorithm?
Naïve Bayes is a probabilistic classification algorithm that relies on Bayes’ Theorem. It assumes that all features in the dataset are independent of one another. Despite this “naïve” assumption, it frequently performs well in real-world applications, particularly in text classification, spam filtering, and sentiment analysis. The algorithm is based on Bayes’ theorem, which states:
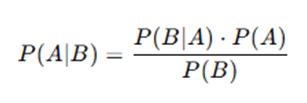
Where:
- P(A∣B) = Posterior probability (probability of class A given data B)
- P(B∣A) = Likelihood (probability of data B given class A)
- P(A) = Prior probability (probability of class A)
- P(B) = Evidence (probability of data B occurring)
Introduction to Naïve Bayes Algorithm
Based on Bayes’ Theorem, the Naïve Bayes algorithm is a supervised learning technique that is typically employed for classification tasks. It is referred to as “naïve” because it makes the assumption that every feature in the dataset is unrelated to every other feature, which may not always be the case in practical situations. Despite this simplification, Naïve Bayes performs well in numerous applications such as spam detection, sentiment analysis, and medical diagnosis. Thomas Bayes developed the Bayes’ Theorem in the 18th century, which forms the basis of Naïve Bayes. The algorithm gained popularity in the field of text classification and information retrieval. It is extensively utilized in document classification, email filtering, and natural language processing (NLP).
Key Concepts of Naïve Bayes Algorithm
- The Bayes Theorem offers a mathematical framework for estimating the likelihood of a hypothesis based on known facts.Here, A represents the class (e.g., Spam/Not Spam), and B represents the observed attributes (e.g., words in an email).
- The algorithm makes the assumption that a feature’s existence in a class is unrelated to the existence of any other features.
- Probabilistic Model: Naïve Bayes calculates the probability of a data instance belonging to each class and assigns the class with the highest probability.
Types of Naïve Bayes Classifiers
Naïve Bayes has different variations based on the type of data it processes:
- Gaussian Naïve Bayes: Assumes that features follow a normal (Gaussian) distribution. Used for continuous data.
- Multinomial Naïve Bayes: Used for text classification problems where data represents word counts or term frequencies.
- Bernoulli Naïve Bayes: Works with binary data (e.g., presence or absence of words in a document).
Importance of Naïve Bayes in Machine Learning
- Fast and Efficient: Requires a small amount of training data to estimate the necessary parameters.
- Handles High-Dimensional Data: Works well even with large feature sets, such as text documents.
- Interpretable Model: Provides a clear probability score, making decision-making straightforward.
Naïve Bayes remains a fundamental algorithm in machine learning, particularly for text-based applications, due to its simplicity and effectiveness.
Detailed Naïve Bayes Algorithm
Based on Bayes’ Theorem, the Naïve Bayes algorithm is a probabilistic classifier. It streamlines computation and increases algorithm efficiency by assuming that all features are conditionally independent given the class label. Step-by-Step Explanation of Naïve Bayes Algorithm are,
Step 1: Understanding Bayes’ Theorem
Naïve Bayes is based on Bayes’ Theorem, which is given by:
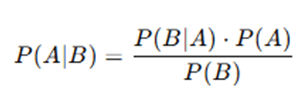
Where:
- P(A∣B) = Posterior probability (probability of class A given data B)
- P(B∣A) = Likelihood (probability of data B given class A)
- P(A) = Prior probability (probability of class A)
- P(B) = Evidence (probability of data B occurring)
In classification, we want to predict the class Ck given the feature set
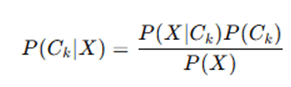
Since P(X) is constant for all classes, we simplify:
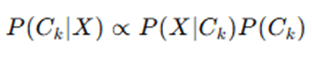
Step 2: Compute the Prior Probability P(Ck)
The prior probability P(Ck) is the proportion of class Ck in the training dataset:
Example: If we have a dataset of 100 emails, where 40 are spam and 60 are not spam, then:
Step 3: Compute the Likelihood P(X∣Ck)
The likelihood is the probability of observing the feature set X given class Ck.
Since Naïve Bayes assumes independence between features, the probability of multiple features occurring together is:

For different types of Naïve Bayes classifiers, the likelihood is computed differently:
- Gaussian Naïve Bayes (for continuous data):
If a feature follows a normal distribution, its probability is computed using the Gaussian (Normal) distribution formula:
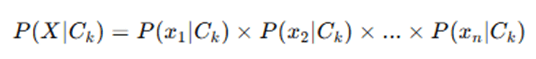
Where:
- μ = mean of feature values in class Ck
- σ = standard deviation of feature values in class Ck
- Multinomial Naïve Bayes (for text data):
Used for word frequency-based text classification. The likelihood is computed as:
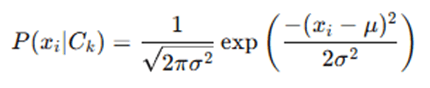
Where ∣V∣ is the vocabulary size, and Laplace smoothing (+1 in numerator) prevents zero probabilities.
- Bernoulli Naïve Bayes (for binary data):
Used when features are binary (e.g., presence or absence of words). The probability is:

Where pi is the probability of word xi appearing in class Ck.
Step 4: Compute the Posterior Probability P(Ck∣X)
The final step is to compute the posterior probability:
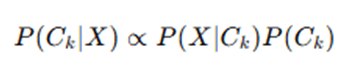
For each class Ck, compute:

The class with the highest probability is assigned as the final prediction.
Step 5: Make the Prediction
Once we have computed the probabilities for each class, we choose the class with the highest probability.
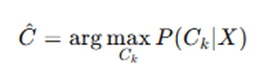
This means the class with the highest probability is the predicted label.
Example: Naïve Bayes for Spam Classification
Imagine we have a dataset with two classes: Spam (S) and Not Spam (N).
| “free” | “win” | “money” | Class | |
| Email 1 | 1 | 1 | 0 | Spam |
| Email 2 | 1 | 1 | 1 | Spam |
| Email 3 | 0 | 1 | 1 | Not Spam |
| Email 4 | 1 | 0 | 0 | Not Spam |
Step 1: Compute Prior Probabilities
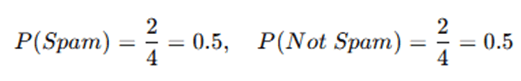
Step2: Compute Likelihood Probabilities
For the word “free”, we count occurrences in spam and not spam emails:

Similar calculations are done for “win” and “money.”
Step 3: Compute Posterior Probabilities for a New Email (“free”, “win”, “money”)

The class with the highest probability is assigned as the predicted label.
Summary
- Calculate prior probabilities for each class.
- Calculate likelihood probabilities for each feature given the class.
- Multiply them together and normalize (Bayes’ theorem).
- Select the class with the highest probability as the final classification.
Naïve Bayes is simple, fast, and effective, making it a popular choice for text classification, spam filtering, and sentiment analysis.
Advantages and Limitations of Naïve Bayes Algorithm
Naïve Bayes is a powerful and widely used classification algorithm. However, it has both strengths and weaknesses that determine its applicability in different scenarios.
Advantages
- Fast and Efficient: Naïve Bayes is computationally efficient and requires very little training time compared to other classification algorithms. It can handle large datasets effectively due to its simple probabilistic calculations.
- Works Well with Small Data: Even with a small dataset, Naïve Bayes performs well because it relies on probability estimations rather than complex optimizations.
- Handles High-Dimensional Data: Naïve Bayes works well with high-dimensional datasets, making it suitable for applications like text classification and spam filtering, where thousands of features (words) exist.
- Robust to Irrelevant Features: Even if some features are irrelevant, Naïve Bayes still performs well because it considers probabilities for each feature separately
- .Effective for Text Classification and Natural Language Processing (NLP): Commonly used in email spam filtering, sentiment analysis, and document classification due to its ability to handle large vocabularies efficiently.
- Handles Missing Data Well: Missing values do not significantly impact classification performance, as the model only considers probabilities of observed features.
- Requires Less Training Data: Since it estimates probabilities from data, Naïve Bayes does not require a large dataset for training compared to deep learning models or decision trees.
Limitations
- Strong Assumption of Feature Independence: The biggest drawback is the assumption that features are independent, which is rarely true in real-world data. Example: In a spam filter, words like “win” and “prize” are related, but Naïve Bayes treats them as independent.
- Struggles with Correlated Features: If two features are highly correlated (e.g., “height” and “weight” in a health dataset), Naïve Bayes may give inaccurate probability estimates.
- Poor Performance with Small Feature Probabilities (Zero Probability Issue): If a feature never appears in the training data for a class, its probability becomes zero, which prevents classification. Solution: Laplace Smoothing (adds a small constant to all probability values).
- Not Ideal for Complex Decision Boundaries: Unlike algorithms like Random Forest or Support Vector Machines (SVMs), Naïve Bayes cannot learn complex relationships between features and is limited to linear decision boundaries.
- Limited for Continuous Data (Gaussian Assumption May Not Hold): The Gaussian Naïve Bayes model assumes that continuous features follow a normal distribution, which may not be true for all datasets.
- Class Conditional Independence Might Not Hold: Example: In medical diagnosis, symptoms are often related (e.g., fever and body aches). Naïve Bayes assumes they are independent, leading to inaccuracies.
Naïve Bayes is an excellent choice for many classification tasks, especially in NLP and spam detection, but its independence assumption limits its accuracy in certain real-world applications.
Applications of Naïve Bayes Algorithm
Naïve Bayes is widely used in various real-world applications, especially in classification tasks where probabilistic decision-making is effective. Due to its speed, simplicity, and ability to handle large datasets, it is commonly used in text processing, medical diagnosis, fraud detection, and recommendation systems.
One common application is spam email filtering, where Naïve Bayes is used to classify emails as spam or not spam by analyzing the occurrence of specific keywords such as “win,” “free,” or “prize” and calculating the probability of the email belonging to a spam or non-spam category. Email services like Gmail, Yahoo Mail, and Outlook employ this technique. In sentiment analysis (opinion mining), the algorithm is used to determine the sentiment (positive, negative, or neutral) in textual data such as movie reviews or customer feedback by analyzing the frequency of words like “excellent” or “terrible.” This method is widely adopted by platforms such as Amazon, Twitter, and Facebook.
Naïve Bayes also plays a crucial role in text classification and news categorization, where it classifies news articles into topics like politics, sports, or technology based on keyword occurrence. Organizations like Google News, BBC, and Reuters rely on it for organizing vast amounts of content. In the field of medical diagnosis and disease prediction, it helps predict diseases based on symptoms like fever, cough, or sore throat, proving especially useful in diagnostic systems and AI-based healthcare platforms.
In fraud detection for banking and insurance, Naïve Bayes evaluates transaction behavior, amounts, and locations to detect anomalies, such as suspicious withdrawals from foreign locations, and is used by major financial institutions like PayPal, Visa, and MasterCard. Similarly, recommendation systems use the algorithm to suggest movies, products, or music based on user history and preferences, making it popular on platforms like Netflix, YouTube, Amazon, and Spotify.
The algorithm is also employed in optical character recognition (OCR) and handwriting recognition, where it converts scanned or handwritten text into digital formats by identifying and classifying character shapes. This is essential in tools like Google Lens and OCR software. In face recognition and image classification, Naïve Bayes is used to identify facial features such as eye shape and nose structure, and is implemented in biometric systems, surveillance, and technologies like Apple Face ID and Facebook tagging.
Furthermore, document classification, including plagiarism detection and legal document sorting, benefits from Naïve Bayes by classifying texts based on keyword patterns, aiding services like Turnitin and law firms. Lastly, in weather prediction, it is used to classify weather types—rainy, sunny, cloudy, or snowy—by analyzing historical temperature and humidity data, supporting basic meteorological systems.
Among its many applications are text processing, fraud detection, medical diagnosis, recommendation systems, and more. Naïve Bayes is a strong, quick, and interpretable algorithm, making it an essential part of many practical AI systems due to its effectiveness in managing big datasets.
Conclusion
Based on Bayes’ Theorem, Naïve Bayes is a straightforward but effective probabilistic classification system. It is quite effective for big datasets and makes computations easier by assuming feature independence. The method works exceptionally effectively in a variety of real-world applications, including as spam filtering, sentiment analysis, medical diagnosis, fraud detection, and recommendation systems, despite its “naïve” presumption. It is a popular option for many machine learning tasks, especially in text classification and natural language processing (NLP), due to its capacity to handle high-dimensional data, operate with minimal datasets, and produce quick predictions. Nevertheless, Naïve Bayes has drawbacks, including its inability to handle correlated data and its assumption of feature independence. Furthermore, the Gaussian Naïve Bayes variant presupposes a normal distribution for continuous data, which isn’t necessarily the case. Techniques like Laplace smoothing, feature engineering, and hybrid models can enhance its performance in spite of these limitations.
Because of its ease of use, speed, and interpretability, Naïve Bayes continues to be a great baseline classifier. Even while it might not always be as accurate as more sophisticated models like Random Forest or Deep Learning, it is nonetheless frequently employed for fast and dependable classification jobs, particularly when probabilistic reasoning is helpful.
Frequently Asked Questions (FAQs)
Q1. Why is it called “Naïve” Bayes?
“Naïve” Bayes gets its name from the assumption that all features are unrelated to one another, which is rarely the case in actual data. The algorithm frequently does well in classification problems in spite of this assumption.
Q2. Can Naïve Bayes be used for regression problems?
No, Naïve Bayes is not appropriate for regression applications; it is a classification method. It is not intended to forecast continuous values, but rather categorical outputs.
Q3. How does Naïve Bayes handle missing data?
By disregarding the missing feature values during probability computations, Naïve Bayes can still function with missing data. To deal with missing data, some systems also employ Laplace smoothing or mean imputation.
Q4. What are the differences between Multinomial, Bernoulli, and Gaussian Naïve Bayes?
- Multinomial Naïve Bayes: Used for text classification, where features represent word frequency.
- Bernoulli Naïve Bayes: Works with binary features (e.g., presence or absence of words).
- Gaussian Naïve Bayes: Used for continuous data, assuming a normal distribution for features.
Q5. Is Naïve Bayes better than other machine learning algorithms?
The dataset determines this. For some applications, such as sentiment analysis and spam filtering, Naïve Bayes is quick, easy, and efficient; nevertheless, it may not work well when features are heavily linked. Algorithms like SVM, Random Forest, or Neural Networks might be superior for complex decision boundaries.









