
What is SVM?
A supervised learning approach for classification and regression problems is called Support Vector Machine (SVM). Pattern recognition, text categorization, and bioinformatics all make extensive use of it, and it works especially well in high-dimensional spaces. Finding the appropriate hyperplane to divide data points of various classes in a dataset is the fundamental goal of support vector machines (SVM). Maximizing the margin (distance) between the decision boundary and the nearest data points for each class is the main concept. The decision boundary is defined in large part by these nearest data points, which are known as support vectors.
SVM can be used for:
- Binary categorization (e.g., emails that are spam or not)
- Classification into many classes (using methods such as One-vs-One and One-vs-All)
- Support Vector Regression, or SVR, is a type of regression analysis.
When the data is not linearly separable, SVM is especially effective. In these situations, it maps the data into a higher-dimensional space where it can be separated using kernel functions.
Introduction to SVM
The supervised learning approach known as Support Vector Machine (SVM) is mainly applied to problems involving regression and classification. Its foundation is the idea of identifying the appropriate hyperplane to divide a dataset’s various classes. In the 1990s, Vladimir Vapnik and his associates presented support vector machines (SVM) as a reliable classification method that excels in complex datasets and high-dimensional spaces. When there are many characteristics relative to the amount of samples, the method performs especially well.
How SVM Works?
- Hyperplane and Decision Boundary: A decision boundary that divides data points into distinct classes is called a hyperplane. The hyperplane is a straight line in two dimensions, a plane in three dimensions, and a more complicated boundary in higher dimensions.
- Support Vectors: Support vectors are the data points that are closest to the hyperplane. These support vectors impact the decision border and define the margin.
- Maximizing the Margin: Finding a hyperplane with the largest margin between the two classes is the main concept of SVM. Better generalization and fewer classification errors are guaranteed by a bigger margin.
- Handling Non-Linearly Separable Data (Kernel Trick): SVM uses kernel functions to convert data into a higher-dimensional space if it cannot be separated linearly.
- The following are examples of common kernel functions: linear, polynomial, radiative basis function (RBF), and sigmoid.
Why Use SVM?
- Performs effectively with datasets that have several dimensions.
- Works well when there are more dimensions than there are samples.
- Able to use kernel functions to handle data that is not linearly separable.
- When the proper regularization is used, it is resistant to overfitting.
SVM is widely used in applications such as image recognition, text classification, medical diagnosis, and bioinformatics.
Detailed Support Vector Machine (SVM) Algorithm
One supervised learning technique for regression and classification is the Support Vector Machine (SVM) algorithm. It determines which hyperplane maximizes the margin between classes. A detailed description of SVM’s operation, including its mathematical formulas, may be found below.
Step 1: Given Dataset
We start with a dataset consisting of n training examples:
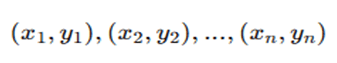
where:
- xi is the feature vector (input).
- yi is the class label (output), where yi∈{−1,+1} for binary classification.
Step 2: Finding the Optimal Hyperplane
A hyperplane is a decision boundary that separates the classes and is defined as:
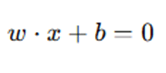
where:
- w is the weight vector (perpendicular to the hyperplane).
- x is the input feature vector.
- b is the bias term.
For a dataset to be linearly separable, it must satisfy the condition:
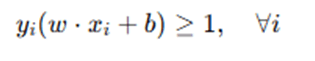
Step 3: Maximizing the Margin
The margin is the perpendicular distance between the closest data points (support vectors) and the hyperplane. The goal of SVM is to maximize the margin, which is mathematically expressed as:
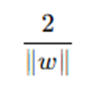
To maximize this margin, we minimize the following objective function:
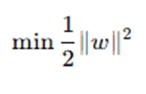
subject to the constraints:
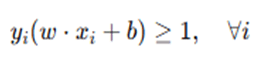
This optimization problem can be solved using Lagrange multipliers and Quadratic Programming.
Step 4: Handling Non-Linearly Separable Data (Kernel Trick)
If the data is not linearly separable, SVM maps it into a higher-dimensional space where it becomes linearly separable. This is done using kernel functions, which compute the dot product in the transformed space without explicitly performing the transformation.
Common Kernel Functions:
- Linear Kernel
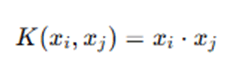
- Polynomial Kernel
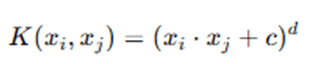
- Radial Basis Function (RBF) Kernel
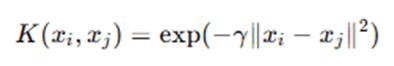
- Sigmoid Kernel

Step 5: Introducing Slack Variables for Soft Margin (Handling Overlapping Classes)
For real-world datasets, perfect separation is often not possible. To allow some misclassification, slack variables ξi are introduced, modifying the constraint to:
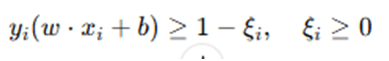
The new optimization problem becomes:
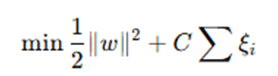
where C is a regularization parameter that controls the trade-off between maximizing the margin and minimizing classification errors.
Step 6: Making Predictions (Decision Function)
Once the optimal www and b are found, we can classify a new data point xxx using the decision function:
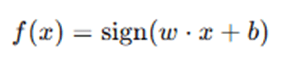
- If f(x)=+1, classify as Class 1.
- If f(x)=−1, classify as Class 2.
One effective supervised learning technique for classification and regression problems is the Support Vector Machine (SVM) algorithm. It operates by determining the best hyperplane to divide a dataset’s classes while maintaining the largest possible buffer between the nearest data points (support vectors). SVM enhances generalization and performs better on unseen data by optimizing this margin. SVM uses kernel functions to convert complex datasets that are not linearly separable into higher-dimensional spaces that facilitate classification. Additionally, soft margin SVM adds slack variables to manage noisy input and overlapping classes, allowing for occasional misclassifications while balancing classification accuracy and margin maximization. Because of these characteristics, SVM is a robust and flexible technique that finds extensive use in domains like financial analysis, medical diagnosis, text categorization, and image recognition.
Advantages and Limitations of SVM Algorithm
Advantages of SVM
- Effective in High-Dimensional Spaces: SVM is helpful for text classification, image recognition, and bioinformatics because it performs well with datasets that contain a lot of information.
- Robust to Overfitting: SVM is less likely to overfit, particularly when kernel functions and appropriate regularization (C parameter) are used.
- Handles Non-Linear Data with Kernel Trick: SVM can separate non-linearly separable data by mapping it onto higher-dimensional spaces using kernel functions.
- Maximizes Margin for Better Generalization : In order to improve generalization to unknown data, the algorithm focuses on maximizing the margin between classes.
- Effective for Both Linear and Non-Linear Classification: Both linearly and non-linearly separable classification problems can be resolved using SVM with the appropriate kernel.
- Works Well for Small and Medium-Sized Datasets: SVM works well with datasets that have a reasonable amount of features and samples.
Limitations of SVM
- Computationally Expensive for Large Datasets: For large datasets, it is slow due to its O(n²) to O(n³) training time complexity.
- Sensitive to Kernel and Hyperparameter Selection: For non-linear situations, selecting the appropriate kernel function, C parameter, and gamma value has a significant impact on SVM performance.
- Not Ideal for Noisy and Overlapping Data : SVM might have trouble determining a suitable decision boundary if there is a lot of class overlap in the data, which could result in incorrect classification.
- Difficult to Interpret : SVM lacks human-readable decision rules and probability estimations, in contrast to logistic regression or decision trees.
- Limited Performance on Imbalanced Datasets: In unbalanced datasets, SVM tends to favor majority classes, necessitating the use of extra methods such class weighting or resampling.
Applications of SVM Algorithm
Because Support Vector Machines (SVM) are so good at classification and regression tasks, they are employed extensively in many different fields. Here are a few of its main uses:
1. Text Classification & Sentiment Analysis
- Spam Detection: Using content features, SVM assists in determining if an email is spam or not.
- Sentiment analysis is the process of identifying the sentiment (positive, negative, or neutral) of social media posts, tweets, and customer reviews.
- Document Categorization: Assists in grouping news stories, scholarly works, or court documents into predetermined groups.
Example: Gmail’s spam filter uses SVM to distinguish spam emails from legitimate ones.
2. Image Recognition & Computer Vision
- Face Detection: SVM classifies pixels as either face or non-face in order to identify faces in photos.
- Handwriting Recognition: Identifies handwritten characters for the purpose of recognizing digits (such as detecting postal codes).
- Medical Image Analysis: Aids in organ segmentation in MRI and CT images, as well as the identification of tumors and cancer cells.
Example: Google’s image search and biometric verification systems use SVM for object recognition.
3. Bioinformatics & Medical Diagnosis
- Disease Classification: Using patient medical information, SVM is used to categorize diseases (e.g., diabetes prediction, cancer detection).
- Classification of Protein Structure: Assists in the investigation of gene expression and the categorization of DNA sequences and proteins.
Example: SVM is used in cancer research to classify malignant and benign tumors.
4. Financial Analysis & Fraud Detection
- Stock Market Prediction: Using past data, SVM forecasts changes in stock prices.
- Credit Scoring & Loan Default Prediction: To assess a customer’s creditworthiness, banks employ SVM.
- Fraud Detection: By examining expenditure trends, this tool assists in locating fraudulent credit card transactions.
Example: Many banks use SVM in fraud detection systems to flag suspicious transactions.
5. Speech & Audio Recognition
- Voice Recognition: Supports voice-to-text programs such as Alexa, Google Assistant, and Siri.
- Music Genre Classification: Using auditory characteristics, music is categorized into many genres.
Example: Spotify and YouTube Music use SVM for recommendation systems and audio classification.
6. Industrial Applications
- Manufacturing fault detection: uses sensor data analysis to find flaws in industrial processes.
- Predictive maintenance: reduces downtime by detecting equipment issues before they happen.
Example: SVM is used in predictive maintenance of aircraft engines and power plants.
7. Cybersecurity & Intrusion Detection
- Virus & Malware Detection: SVM uses behavioral analysis to determine whether a file is safe or dangerous.
- Network Intrusion Detection: Prevents cyberattacks by identifying questionable activity within a network.
Example: Companies like Symantec and McAfee use SVM for real-time cybersecurity monitoring.
8. Agriculture & Climate Prediction
- Crop Disease Detection: Examines crop photos to identify illnesses and recommend remedies.
- Weather Forecasting: uses meteorological data to forecast trends of temperature, precipitation, and climate.
Example: Farmers use SVM-based apps to monitor soil health and optimize irrigation.
A strong and adaptable algorithm, Support Vector Machine (SVM) finds extensive application in image recognition, cybersecurity, healthcare, and many other fields. It is a crucial tool for contemporary AI applications because of its capacity to handle high-dimensional data.
Conclusion
A popular supervised learning technique for classification and regression problems is the Support Vector Machine (SVM). It is quite effective in many real-world applications since it can handle high-dimensional data and identify the best hyperplane for class separation. SVM is a strong option for jobs like text classification, image identification, medical diagnosis, and financial analysis because of its novel method of maximizing the margin between classes, which enhances generalization. Furthermore, SVM can effectively handle non-linearly separable data by leveraging kernel functions, increasing its applicability in a variety of problem domains. SVM has many drawbacks despite its benefits, including a high computational complexity, sensitivity to parameter choice, and challenges managing sizable datasets with overlapping classes. Achieving optimal performance requires selecting the appropriate kernel and regularization parameters. Furthermore, extra methods like class weighting or data resampling could be needed for unbalanced datasets in order to increase classification accuracy. All things considered, SVM is still a basic machine learning method with solid theoretical underpinnings and real-world applicability in a variety of sectors. Its effectiveness in resolving intricate classification issues makes it a useful instrument in domains such as predictive analytics, bioinformatics, cybersecurity, and artificial intelligence. SVM is still a dependable option even if deep learning models are becoming more and more popular, particularly in situations where interpretability and computational efficiency are crucial.
Frequently Asked Questions (FAQs)
Q1. What is the main objective of SVM?
Finding the ideal hyperplane to maximize the margin between data points of distinct classes is the main objective of support vector machines (SVM). Better generalization to unknown data is therefore ensured.
Q2. What are support vectors in SVM?
The data points that are closest to the decision boundary (hyperplane) are known as support vectors. These factors affect the final classifier and establish the margin. SVM is memory-efficient since it only requires these support vectors.
Q3. What is the role of the kernel function in SVM?
By converting non-linearly separable data into a higher-dimensional space where it can be linearly separable, the kernel function aids SVM in handling such data. Linear, polynomial, radial basis function (RBF), and sigmoid kernels are examples of common kernel functions.
Q4. How does SVM handle multi-class classification?
Although SVM was first created for binary classification, it may be used for multi-class classification by using:
- One-vs-One (OvO): Chooses the most commonly predicted class by building classifiers for every potential pair of classes.
- One-vs-All (OvA): Treats all other classes as a single category while training distinct classifiers for each class.
Q5. What are the differences between SVM and logistic regression?
- SVM determines the best hyperplane to maximize the margin, whereas logistic regression uses a sigmoid function to estimate probabilities.
- While logistic regression is more interpretable and computationally economical for simpler issues, support vector machines (SVM) perform better for high-dimensional data.
- While logistic regression is by nature linear, support vector machines (SVM) can apply kernels for data that is not linearly separable.









