
What is Infomap Algorithm?
The Infomap Algorithm is a powerful method used for community detection in complexnetworks. It is based on principles from information theory, particularly the idea of compressing information to reveal meaningful structures within a network. In simple terms, Infomap identifies groups (or communities) of nodes in a network such that there are dense connections within groups and sparser connections between them. What makes Infomap unique is that it treats the problem as an information compression task, using the movement of a random walker across the network to uncover its structure. Rather than simply clustering nodes based on connectivity, Infomap seeks to minimize the description length of a random walk, meaning it tries to encode the movement of information in the most efficient way. Communities emerge naturally as regions where the random walker tends to stay longer.
Introduction of Infomap Algorithm
In modern data science and network analysis, detecting hidden patterns in networks is crucial. Networks appear everywhere — from social media graphs, biological systems, transport networks, to communication systems. Traditional clustering algorithms often rely on structural properties such as edge density. However, Infomap introduces a dynamic perspective by focusing on how information flows through the network. The algorithm was introduced by Rosvall and Bergstrom (2008) and quickly became one of the most effective methods for community detection due to its:
- Strong theoretical foundation in information theory
- High accuracy in identifying real-world communities
- Ability to handle large-scale networks
The key idea behind Infomap is:
“A good clustering is one that allows us to describe the movement of a random walker using the fewest number of bits.” This perspective transforms the community detection problem into an optimization problem, where the goal is to minimize the Map Equation — the core mathematical formulation of Infomap.
Detailed Infomap Algorithm
3.1 Core Concept: The Map Equation
The Infomap algorithm is built around the Map Equation, which measures the theoretical limit of how concisely one can describe the trajectory of a random walker on a network. The Map Equation is defined as:

Where:
- L(M): Average description length per step
- q↷: Probability that the random walk exits a module
- H(Q): Entropy of inter-module movements
- p↻i: Probability of staying within module i
- H(Pi): Entropy within module i
- m: Number of modules (communities)
3.2 Entropy Calculations
Entropy is used to measure uncertainty in movement:

This formula is applied both:
- Between communities (global movement)
- Within communities (local movement)
3.3 Algorithm Steps
Step 1: Initialize Network
- Represent the network as a graph G(V,E)
- Nodes V, edges E
Step 2: Simulate Random Walk
- A random walker moves from node to node based on transition probabilities
- Transition probability:

Step 3: Assign Initial Communities
- Each node starts as its own community
Step 4: Calculate Map Equation
- Compute description length using current partition
Step 5: Optimize Community Structure
- Move nodes between communities
- Accept moves that reduce L(M)
Step 6: Iterative Refinement
- Repeat until no further reduction is possible
Step 7: Hierarchical Clustering (Optional)
- Build multi-level communities
The Infomap algorithm begins by representing a network as a graph consisting of nodes and edges, where edges may carry weights indicating the strength of connections. A random walker is then introduced into the network, which moves probabilistically from one node to another based on the relative weights of outgoing edges. This movement simulates how information flows through the system. Initially, each node is considered its own community, which represents the most granular partition possible. The algorithm then calculates the Map Equation, which quantifies how efficiently the random walk can be encoded using the current partitioning of the network. The goal is to reduce this encoding length. Next, the algorithm begins an optimization process. It iteratively examines each node and considers moving it into neighboring communities. After each potential move, the Map Equation is recalculated. If the move results in a shorter description length, it is accepted; otherwise, it is rejected. This process continues in multiple passes until no further improvements can be made. At this point, the algorithm may compress communities into super-nodes and repeat the process to identify hierarchical structures. The final output is a partition of the network into communities that minimize the Map Equation, effectively capturing the underlying structure of the network.
Example of How Infomap Algorithm Works
Network Structure
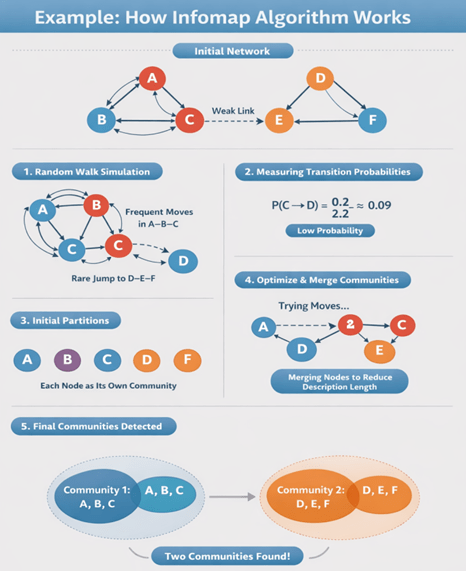
Let us consider a simple network with 6 nodes:
- Nodes: A, B, C, D, E, F
- Connections:
- A–B, B–C, C–A → Cluster 1
- D–E, E–F, F–D → Cluster 2
- One weak link between C and D
Visual Representation of the Network
Step-by-Step Working of Infomap on This Network
Step 1: Initial Setup
- Each node is treated as an independent community:
- {A}, {B}, {C}, {D}, {E}, {F}
- The algorithm assumes a random walker moving through the network.
Step 2: Random Walk Behavior
The random walker moves based on connectivity:
- Inside Cluster 1 (A–B–C):
- A → B → C → A (high probability loop)
- Inside Cluster 2 (D–E–F):
- D → E → F → D (another loop)
- Between clusters:
- C → D (rare, weak connection)
This means:
- The walker spends more time within clusters
- Less time jumping between clusters
Step 3: Transition Probabilities
Assume all internal edges have weight = 1
Weak edge (C–D) has weight = 0.2
Example probability from node C:
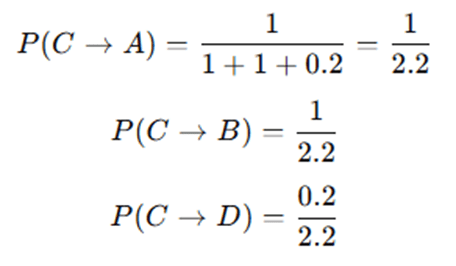
Clearly:
- Staying inside cluster ≈ high probability
- Moving outside ≈ low probability
Step 4: Encoding the Random Walk
Infomap encodes the movement using:
- Short codes within communities
- Special codes when switching communities
Without communities:
- Every node needs a unique code
- Longer description length
With communities:
- Use:
- Module codebook (for switching clusters)
- Local codebooks (for nodes inside clusters)
This reduces total encoding length
Step 5: Community Detection Using Map Equation
Infomap evaluates two scenarios:
Case 1: No Communities (All nodes separate)
- Every step requires full node encoding
- High entropy
- Long description length
Case 2: Two Communities
- Community 1: A, B, C
- Community 2: D, E, F
Now:
- Frequent movements inside clusters use short codes
- Rare jumps use exit codes
This significantly reduces:

Step 6: Why Infomap Chooses Two Communities
Because:
- Random walker stays longer in:
- A–B–C
- D–E–F
- Few transitions between clusters
- Compression is maximized
Therefore:
Optimal partition:
- Community 1: {A, B, C}
- Community 2: {D, E, F}
Intuition Behind the Result
Think of it like this:
- Inside a city → you move frequently between streets
- Between cities → you travel rarely
Infomap identifies “cities” (communities) by observing movement patterns.
Flow Summary
- Build graph
- Simulate random walk
- Measure movement probabilities
- Encode movement efficiently
- Minimize description length
- Detect communities
Key Insight
Infomap does not just look at connections — it looks at how information flows.
Because the flow is:
- Dense inside clusters
- Sparse between clusters
The algorithm naturally discovers meaningful communities.
Final Output
| Community | Nodes |
| 1 | A, B, C |
| 2 | D, E, F |
Advantages and Disadvantages of Infomap Algorithm
Advantages
- High Accuracy: Infomap is widely recognized for its high accuracy in community detection. By leveraging the Map Equation and modeling information flow, it often outperforms traditional clustering methods such as modularity-based algorithms. This makes it especially effective for complex and real-world networks where simple structural approaches may fail.
- Information-Theoretic Foundation: The algorithm is built on strong mathematical principles from information theory, particularly entropy and data compression. This solid theoretical base ensures that the results are not arbitrary but are grounded in a well-defined optimization objective—minimizing the description length of a random walk.
- Captures Flow Dynamics: Unlike many clustering techniques that only consider static connections, Infomap focuses on how information flows through the network. By simulating a random walker, it captures dynamic behavior, leading to more meaningful and realistic communities that reflect actual interaction patterns.
- Scalable: Infomap is designed to be efficient and scalable, making it suitable for analyzing large-scale networks such as social media graphs, biological systems, and communication networks. With optimized implementations, it can handle millions of nodes and edges effectively.
- Hierarchical Detection: Another key strength is its ability to detect hierarchical (multi-level) community structures. Infomap can identify both large communities and smaller sub-communities within them, providing deeper insights into the organization of complex networks.
Disadvantages
- Computational Complexity: Despite its scalability, Infomap can become computationally intensive for extremely large or dense networks. The iterative optimization process and repeated evaluation of the Map Equation may require significant computational resources.
- Sensitivity to Edge Weights: The performance of Infomap depends heavily on accurate edge weights. If the weights do not properly represent the strength of relationships, the resulting communities may be misleading or less meaningful.
- Random Walk Assumption: Infomap is based on the assumption that network behavior can be modeled using a random walk process. However, this assumption may not hold true for all types of networks, especially those where interactions do not follow flow-based dynamics.
- Local Optima Problem: Like many optimization algorithms, Infomap may sometimes get stuck in local optima, meaning it does not always guarantee finding the absolute best (global) solution for the Map Equation. This can lead to slightly suboptimal community detection in certain cases.
Applications of Infomap Algorithm
Infomap is a versatile algorithm that is widely used across multiple domains due to its ability to detect meaningful communities based on information flow. Below are its key applications:
- Social Network Analysis: In social networks, Infomap helps identify communities of users who interact frequently. It is commonly applied to platforms like Facebook and Twitter to detect friend groups, interest-based communities, or influencer clusters. By analyzing connection patterns and communication flow, it enables the identification of groups with shared interests, behaviors, or social ties, which is valuable for marketing, content targeting, and user engagement strategies.
- Biological Systems: By revealing intricate cellular relationships, Infomap is essential to the analysis of biological systems. It is used to find functional modules in protein-protein interaction networks and to find cooperative gene groups in gene regulatory networks. This aids scientists in comprehending disease mechanisms and biological pathways.
- Networks of Information: Infomap facilitates the effective organization and analysis of massive datasets in information systems. It is used in web page clustering to classify webpages according to content and links, and in citation networks to group relevant research publications. These programs enhance overall information retrieval, knowledge discovery, and search accuracy.
- Systems of Transportation: Infomap is a very useful tool for traffic and transportation network analysis. It shows highly connected areas, finds bottlenecks, and recognizes trends in traffic movement. This makes it possible to plan infrastructure and make better routing decisions, which improves traffic control and lessens congestion.
- Cybersecurity: Infomap is used in cybersecurity to find abnormalities and odd patterns in network traffic. It aids in tracking the propagation of malware, identifying suspicious groupings that can point to cyberattacks, and analyzing system communications. Network security is strengthened and threat detection is improved as a result.
- Systems of Recommendations: Recommendation systems frequently employ infomap to enhance customisation. It enables platforms to provide more accurate suggestions by grouping people with similar tastes and things with comparable features. In e-commerce, streaming services, and other digital platforms, this improves the user experience.
Conclusion
The Infomap Algorithm has emerged as one of the most powerful and conceptually rich approaches for community detection in complex networks. Unlike traditional clustering techniques that rely purely on structural properties such as edge density or modularity, Infomap introduces a dynamic and information-theoretic perspective. By modeling the movement of a random walker and minimizing the description length of its path, the algorithm effectively transforms community detection into a data compression problem. This unique approach allows Infomap to uncover communities that are not only structurally cohesive but also functionally meaningful, reflecting how information, signals, or interactions actually flow within the network. As a result, it provides deeper insights into real-world systems such as social networks, biological interactions, communication systems, and transportation infrastructures. Another significant strength of Infomap lies in its ability to capture both local and global structures. It identifies tightly connected groups while also considering how these groups interact with one another. Furthermore, its support for hierarchical clustering enables the discovery of multi-level community structures, offering a more nuanced understanding of complex systems. Despite its advantages, Infomap is not without limitations. It can be computationally demanding for very large or dense networks, and its reliance on the random walk model may not always align with the behavior of certain systems. Additionally, like many optimization-based algorithms, it may occasionally converge to local optima rather than the global best solution. However, these limitations are generally outweighed by its strengths. Infomap’s accuracy, scalability, and strong theoretical foundation make it a preferred choice for researchers and practitioners across various domains. As networks continue to grow in scale and complexity in the era of big data, algorithms like Infomap will play a crucial role in revealing hidden patterns, improving decision-making, and advancing our understanding of interconnected systems.
Frequently Asked Questions (FAQs)
What makes Infomap different from other clustering algorithms?
Infomap differs from traditional clustering methods because it focuses on information flow and compression rather than just structural connectivity. While many algorithms group nodes based on edge density or modularity, Infomap analyzes how a random walker moves through the network and identifies communities that allow for the most efficient encoding of this movement. This results in more realistic and functionally meaningful clusters.
What is the Map Equation in Infomap?
The Map Equation is the core mathematical formulation used in Infomap. It measures how efficiently the path of a random walker can be described given a particular partition of the network. By minimizing this equation, Infomap identifies the optimal community structure. In essence, it quantifies the trade-off between within-community movements and between-community transitions, ensuring the most compressed representation of the network.
Is Infomap suitable for large networks?
Yes, Infomap is designed to be scalable and efficient, making it suitable for large networks with thousands or even millions of nodes. Optimized implementations can handle complex datasets effectively. However, performance may vary depending on factors such as network density, hardware resources, and the specific implementation used.
Can Infomap detect hierarchical communities?
Yes, one of the key strengths of Infomap is its ability to detect hierarchical (multi-level) community structures. It can identify large communities and further subdivide them into smaller sub-communities. This hierarchical capability provides deeper insights into how networks are organized at different levels of granularity.
Where is Infomap commonly used?
Infomap is widely applied across multiple domains, including:
- Social networks → detecting user communities and interaction groups
- Biological systems → identifying functional modules in gene and protein networks
- Cybersecurity → detecting anomalies and attack patterns in network traffic
- Recommendation systems → grouping users and items for personalization
Its flexibility and effectiveness make it a valuable tool wherever network structure and information flow analysis are important.







