
What is CatBoost Algorithm?
CatBoost (Categorical Boosting) is a gradient boosting algorithm developed by Yandex. It is specifically designed to handle categorical features efficiently and automatically, without requiring extensive preprocessing such as one-hot encoding. CatBoost belongs to the family of Gradient Boosting Decision Tree (GBDT) algorithms, similar to XGBoost and LightGBM. However, it introduces innovative techniques like: Ordered Boosting, Target-based statistics for categorical features and Symmetric (oblivious) trees. These enhancements make CatBoost highly effective for structured/tabular datasets, especially those containing many categorical variables. In simple terms, CatBoost builds multiple decision trees sequentially, where each new tree corrects the errors of the previous trees using gradient descent optimization.
Introduction of CatBoost Algorithm
Machine learning problems often involve structured data with features like:
- Gender
- Country
- Product category
- Device type
- Payment method
Traditional algorithms require encoding these categorical features into numerical values using techniques like:
- One-hot encoding
- Label encoding
- Target encoding
However, these methods can:
- Increase dimensionality
- Introduce data leakage
- Reduce model efficiency
CatBoost solves this by introducing a novel ordered target statistics encoding, preventing data leakage and improving model stability.
CatBoost stands out because:
- It requires minimal data preprocessing.
- It reduces overfitting using ordered boosting.
- It works efficiently on CPU and GPU.
- It handles categorical and numerical features seamlessly.
The algorithm is widely used in:
- Ranking systems
- Recommendation engines
- Fraud detection
- Customer churn prediction
- Search engine optimization
Detailed CatBoost Algorithm
CatBoost is based on Gradient Boosting, where the goal is to minimize a loss function LLL.
3.1 Objective Function
Given dataset:

Where:
- xi = feature vector
- yi = target value
The model prediction:

The objective function:
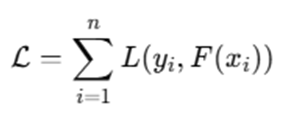
The aim is to minimize this loss.
3.2 Gradient Boosting Principle
The model is built as an additive model:
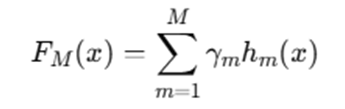
Where:
- hm(x) = decision tree
- γm = learning rate
- M = number of trees
At each iteration m, we compute residuals:

These residuals represent the gradient direction.
3.3 Ordered Boosting
Traditional boosting suffers from prediction shift, caused by using the same data point for gradient estimation.
CatBoost solves this by:
- Creating random permutations of data.
- Calculating target statistics using only previous samples in permutation.
Mathematically:

Where:
- P = prior
- a = smoothing parameter
This avoids target leakage.
3.4 Handling Categorical Features
For categorical feature C, CatBoost calculates:

This is called target statistics encoding.
3.5 Symmetric Trees (Oblivious Trees)
Unlike traditional trees, CatBoost uses symmetric trees.
Each level uses the same split condition.
Tree depth = d
Number of leaves:
2d
Advantages:
- Faster inference
- Balanced tree
- Reduced overfitting
3.6 Algorithm Steps (Mathematical Overview)
- Initialize model:

- For each iteration m=1…M:
a) Compute gradients:
rim
b) Fit symmetric tree hm(x)
c) Update:

Where:
- η = learning rate
CatBoost begins by initializing the model with a constant value that minimizes the loss function over the entire dataset. In regression problems, this is usually the mean of the target variable, while in classification problems, it may be the log-odds of class probabilities. This initial model serves as the starting point for iterative improvement. Next, the algorithm creates a random permutation of the training dataset. This permutation plays a crucial role in preventing data leakage when handling categorical variables. Instead of computing target statistics using the full dataset, CatBoost calculates the encoding for each sample using only the samples that appear before it in the permutation order. This ensures that the model does not use future information.
After preprocessing categorical features using ordered target statistics, the algorithm computes gradients of the loss function with respect to predictions. These gradients represent the direction in which predictions need to be adjusted to reduce error. The algorithm then builds a symmetric decision tree to approximate these gradients. At each level of the tree, the same splitting rule is applied to all nodes at that depth. This structure simplifies tree construction and improves computational efficiency.
Once the tree is constructed, its predictions are scaled by a learning rate and added to the existing model. This process is repeated for a predefined number of iterations or until convergence criteria are met. Through this iterative boosting mechanism, CatBoost gradually reduces the loss function and improves predictive accuracy.
Example of How CatBoost Works
Example: Customer Churn Prediction (Detailed Explanation)
Let us understand how CatBoost works internally using a simplified Customer Churn Prediction example. We will walk through every step mathematically and conceptually.
Problem Statement
We want to predict whether a customer will churn (Yes/No) based on:
| CustomerID | Country | PlanType | MonthlyCharges | Churn |
| 1 | India | Premium | 500 | Yes |
| 2 | USA | Basic | 200 | No |
| 3 | India | Basic | 300 | No |
| 4 | USA | Premium | 450 | Yes |
Target variable:

Where:
- Yes = 1
- No = 0
Converted dataset:
| CustomerID | Country | PlanType | MonthlyCharges | y |
| 1 | India | Premium | 500 | 1 |
| 2 | USA | Basic | 200 | 0 |
| 3 | India | Basic | 300 | 0 |
| 4 | USA | Premium | 450 | 1 |
Step 1: Encode Categorical Features Using Ordered Statistics
CatBoost does NOT use one-hot encoding. Instead, it applies Ordered Target Encoding.
Step 1.1: Create Random Permutation
Suppose CatBoost creates this random permutation:
[3,1,4,2]Meaning we process samples in this order.
Step 1.2: Encode “Country” Feature
Formula:

Where:
- P = prior (global mean)
- a = smoothing parameter
Step 1.3: Compute Global Mean
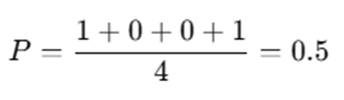
Now Encode Step-by-Step
Observation 3 (India, Basic, y=0)
No previous samples.

Observation 1 (India, Premium, y=1)
Previous: Observation 3 (India, y=0)
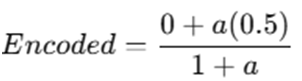
If a=1:

Observation 4 (USA, Premium, y=1)
No previous USA samples.
Encoded=0.5
Observation 2 (USA, Basic, y=0)
Previous USA sample: Observation 4 (y=1)

Now categorical features are replaced with numeric encoded values.
This prevents target leakage, because each row uses only past data.
Step 2: Initialize Model Prediction
For binary classification using log-loss:
Initial prediction:
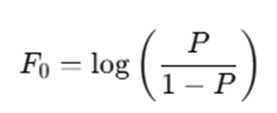
Since:
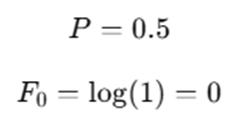
So:
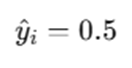
for all samples.
Step 3: Compute Residual Errors (Gradients)
Using Log Loss:

Gradient:

Since pi=0.5
Compute residuals:
| Customer | y | Prediction | Residual |
| 1 | 1 | 0.5 | 0.5 |
| 2 | 0 | 0.5 | -0.5 |
| 3 | 0 | 0.5 | -0.5 |
| 4 | 1 | 0.5 | 0.5 |
These residuals indicate:
- Positive residual → increase prediction
- Negative residual → decrease prediction
Step 4: Build Symmetric Tree
CatBoost builds oblivious (symmetric) trees.
Suppose tree depth = 2.
Each level uses the SAME split condition.
Level 1 Split
Condition:

Left Node → No
Right Node → Yes
Level 2 Split (Same Condition for Both Nodes)
Condition:

This creates:

Each leaf stores average residual.
Example:
| Leaf | Avg Residual |
| Leaf 1 | -0.5 |
| Leaf 2 | 0.5 |
| Leaf 3 | -0.5 |
| Leaf 4 | 0.5 |
Step 5: Update Model
Update rule:
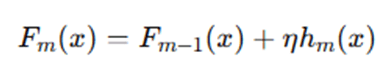
If learning rate:

For residual = 0.5:

New probability:

For residual = -0.5:

Predictions move closer to actual values.
Step 6: Repeat Until Convergence
CatBoost repeats:
- Compute new residuals
- Build new symmetric tree
- Update predictions
After many trees:
Predictions converge toward true labels.
Final prediction rule:


Advantages and Disadvantages of CatBoost Algorithm
CatBoost has become one of the most powerful gradient boosting algorithms for structured data, especially when categorical variables are involved. However, like any machine learning algorithm, it comes with both strengths and limitations. Below is a detailed discussion of its advantages and disadvantages.
Advantages of CatBoost
- Native Handling of Categorical Features : One of the most significant advantages of CatBoost is its ability to handle categorical features directly without requiring manual preprocessing techniques such as one-hot encoding or label encoding. Traditional algorithms like XGBoost and LightGBM typically require categorical features to be converted into numerical representations before training. CatBoost uses ordered target statistics encoding, which converts categorical values into numerical representations in a way that avoids data leakage. This built-in mechanism simplifies data preprocessing pipelines and reduces the risk of introducing bias during encoding. It is especially beneficial for real-world datasets with high-cardinality categorical variables such as product IDs, customer IDs, or location codes.
- Reduces Overfitting via Ordered Boosting: CatBoost introduces a novel technique called Ordered Boosting, which significantly reduces overfitting. Traditional gradient boosting methods can suffer from prediction shift because the same data points are used to compute both target statistics and gradients. CatBoost solves this problem by using random permutations and computing statistics only from previously observed samples. This prevents target leakage and ensures that the model generalizes better to unseen data. As a result, CatBoost tends to produce more stable and reliable predictions, especially on smaller datasets.
- Requires Minimal Hyperparameter Tuning: Many machine learning models require extensive hyperparameter tuning to achieve optimal performance. CatBoost, however, performs well even with default settings. Its built-in mechanisms for handling categorical variables, regularization, and balanced tree construction reduce the need for complex parameter adjustments. While tuning can still improve performance, CatBoost often provides strong baseline results without heavy experimentation. This makes it highly practical for rapid prototyping and real-world deployment scenarios.
- High Accuracy on Tabular Data: CatBoost is particularly strong when working with structured or tabular datasets. In many industry benchmarks, it performs competitively or even better than other boosting algorithms. The combination of: Ordered boosting, Symmetric trees, and Effective categorical encoding allows CatBoost to capture complex feature interactions while maintaining robustness. For datasets dominated by structured business data (finance, marketing, customer analytics), CatBoost often delivers state-of-the-art performance.
- Fast Inference Using Symmetric Trees: CatBoost uses oblivious (symmetric) trees, where the same split condition is applied at each level of the tree. This structure allows for efficient prediction because decision paths are highly optimized. Since symmetric trees have predictable structure, inference can be implemented using bitwise operations, leading to faster execution compared to traditional asymmetric trees. This makes CatBoost suitable for applications requiring real-time predictions, such as recommendation systems or fraud detection systems.
- Supports GPU Acceleration: CatBoost provides native GPU support, allowing it to train efficiently on large datasets. GPU acceleration significantly speeds up training time, especially when dealing with high-dimensional data or large numbers of boosting iterations. This makes CatBoost scalable for enterprise-level applications and big data environments, where computational efficiency is critical.
Disadvantages of CatBoost
- Training Can Be Slower Than LightGBM: Although CatBoost is optimized for efficiency, its training time can sometimes be slower compared to LightGBM, particularly on extremely large datasets. LightGBM uses histogram-based optimization and leaf-wise tree growth, which can make it faster in certain scenarios. CatBoost’s ordered boosting and permutation-based encoding introduce additional computational overhead during training.
- Smaller Community Compared to XGBoost: While CatBoost is widely respected, it has a smaller community compared to XGBoost. XGBoost has been available longer and has broader adoption across academic research and industry applications. A smaller community may mean: Fewer third-party tutorials, Limited community support, Fewer pre-built integrations However, CatBoost documentation and official resources remain strong and well-maintained.
- Higher Memory Consumption for Large Models: Because CatBoost builds multiple symmetric trees and stores target statistics for categorical features, large models may consume more memory compared to simpler models. This can become a limitation when deploying models in memory-constrained environments such as embedded systems or lightweight applications.
- Not Ideal for Unstructured Data: CatBoost is primarily designed for structured, tabular data. It is not inherently suited for unstructured data types such as: Raw images, Audio signals, Free-form text. Deep learning frameworks like convolutional neural networks (CNNs) or transformer-based models are more appropriate. CatBoost can still be used if meaningful numerical features are extracted beforehand, but it is not optimized for raw unstructured inputs.
CatBoost is a powerful and robust gradient boosting algorithm, particularly well-suited for structured datasets with categorical features. Its ability to reduce overfitting, minimize preprocessing effort, and deliver high accuracy makes it a preferred choice for many business applications. However, considerations such as training speed, memory usage, and suitability for unstructured data should be evaluated before selecting it for a specific use case.
Applications of CatBoost Algorithm
The CatBoost algorithm, developed by Yandex, has become a powerful solution for real-world machine learning problems involving structured data. Its ability to handle categorical features natively, reduce overfitting using ordered boosting, and deliver strong predictive performance makes it highly suitable for various industry domains. Below are the major application areas where CatBoost is widely used.
Finance: The finance industry deals extensively with structured datasets containing categorical variables such as customer segments, transaction types, credit categories, and geographic regions. CatBoost’s built-in categorical encoding makes it particularly effective in this domain.
- Credit Scoring: Financial institutions use CatBoost to assess a borrower’s creditworthiness. Features such as employment type, income category, loan type, and payment history often include categorical values. CatBoost captures complex interactions between these features and predicts the probability of loan default with high accuracy. Its ordered boosting mechanism reduces overfitting, which is crucial in high-stakes financial decision-making where incorrect predictions can result in major losses.
- Fraud Detection: Fraud detection systems rely on transaction-level data containing merchant category, transaction type, device ID, and location. CatBoost can model subtle patterns in fraudulent behavior by effectively learning from categorical transaction attributes. Its fast inference capability using symmetric trees makes it suitable for real-time fraud detection systems where decisions must be made instantly.
- Risk Modeling: CatBoost is used in financial risk modeling for predicting credit risk, market risk, and operational risk. Since risk datasets often include categorical policy classifications and account types, CatBoost provides superior performance compared to traditional regression models.
E-Commerce: E-commerce platforms generate massive structured datasets with numerous categorical features such as product categories, customer segments, and payment methods. CatBoost performs exceptionally well in such environments.
- Product Recommendation: Online platforms use CatBoost to recommend products based on user browsing history, purchase patterns, and product attributes. Since many of these attributes are categorical, CatBoost’s encoding strategy improves recommendation accuracy. Its ability to capture non-linear relationships between features enhances personalized recommendations.
- Customer Lifetime Value (CLV) Prediction: Businesses use CatBoost to predict customer lifetime value by analyzing transaction frequency, customer demographics, and subscription types. Accurate CLV predictions help companies optimize marketing spend and retention strategies.
- Churn Prediction: Customer churn prediction is one of the most common applications of CatBoost. By analyzing customer behavior, subscription plans, and usage patterns, the model predicts whether a customer is likely to leave. Early detection enables businesses to implement retention strategies.
Healthcare: Healthcare datasets often contain structured information such as patient categories, diagnosis codes, treatment types, and hospital departments. CatBoost can model these features effectively.
- Disease Prediction: CatBoost is used to predict diseases based on patient symptoms, demographic information, and medical history. Its ability to handle categorical attributes like diagnosis codes and medication types improves predictive accuracy.
- Patient Risk Classification: Hospitals and healthcare providers use CatBoost to classify patients into risk categories (low, medium, high risk). This helps in prioritizing treatment and resource allocation.
Because healthcare decisions require high reliability, CatBoost’s stability and reduced overfitting are particularly beneficial.
Marketing: Marketing analytics heavily relies on structured customer data. CatBoost is commonly used for predictive modeling and segmentation tasks.
- Customer Segmentation: Businesses use CatBoost to group customers based on purchasing behavior, demographics, and interaction history. Accurate segmentation allows for targeted marketing campaigns and improved personalization.
- Campaign Response Prediction: Marketing teams use CatBoost to predict whether a customer will respond to a promotional campaign. By analyzing past responses and customer attributes, the algorithm estimates response probability and improves campaign ROI.
Search and Ranking
CatBoost is highly effective in ranking problems and was originally optimized for ranking tasks by its creators at Yandex.
- Search Result Ranking: Search engines use CatBoost to rank search results based on relevance. Features such as query type, user location, and content category are often categorical, making CatBoost well-suited for such tasks. Its symmetric tree structure enables fast inference, which is critical for search systems handling millions of queries per second.
- Ad Click Prediction: Digital advertising platforms use CatBoost to predict click-through rates (CTR). Features like ad category, user device type, and time of day are categorical in nature. CatBoost learns complex interactions among these features and improves ad targeting accuracy.
Why CatBoost Excels in Real-World Business Applications
CatBoost performs exceptionally well in business environments because:
- Real-world datasets are dominated by categorical features.
- It reduces preprocessing complexity.
- It minimizes overfitting through ordered boosting.
- It offers strong performance with minimal hyperparameter tuning.
- It supports both CPU and GPU training for scalability.
As a result, CatBoost has become a reliable choice for industries that rely on structured data and predictive analytics.
Conclusion
CatBoost, developed by Yandex, represents a significant advancement in the field of gradient boosting algorithms, particularly for structured and tabular datasets. While traditional Gradient Boosting Decision Tree (GBDT) models have demonstrated strong predictive performance over the years, they often struggle with categorical feature handling and prediction shift issues. CatBoost was specifically engineered to address these limitations in a systematic and mathematically robust way. One of the most distinctive contributions of CatBoost is its Ordered Boosting mechanism, which eliminates prediction shift by ensuring that target statistics for each data point are calculated using only previously observed samples in a random permutation. This prevents target leakage, improves generalization, and enhances the stability of the model—especially on smaller datasets. Another major innovation is the use of symmetric (oblivious) decision trees. Unlike traditional asymmetric trees that grow unevenly, symmetric trees apply the same split condition across each level of the tree. This balanced structure:
- Reduces model variance
- Speeds up inference
- Simplifies implementation
- Improves computational efficiency
When compared to widely used algorithms such as XGBoost and LightGBM, CatBoost offers several unique advantages. While XGBoost and LightGBM require manual encoding of categorical variables, CatBoost handles them natively through ordered target statistics encoding. This not only simplifies preprocessing pipelines but also reduces the risk of introducing bias through improper encoding strategies. Furthermore, CatBoost requires relatively minimal hyperparameter tuning to achieve strong baseline performance. Its built-in regularization techniques, efficient tree construction, and automatic handling of missing values make it highly practical for industry deployment. The algorithm also supports GPU acceleration, making it scalable for large datasets and enterprise-level applications.
In real-world business contexts—such as finance, e-commerce, healthcare, marketing, and search ranking—datasets are often dominated by categorical features. CatBoost excels in these environments because it is specifically optimized for such data structures. Its ability to automatically encode categories, prevent data leakage, and build stable ensemble models makes it one of the most reliable algorithms for structured data problems. As machine learning continues to evolve, deep learning dominates unstructured data tasks such as image and speech recognition. However, for tabular datasets—the backbone of most business analytics—CatBoost remains one of the most powerful, stable, and production-ready algorithms available today.
Frequently Asked Questions (FAQs)
Is CatBoost better than XGBoost?
CatBoost often performs better than XGBoost when the dataset contains a large number of categorical variables. Since CatBoost handles categorical features natively using ordered target encoding, it avoids the need for manual preprocessing steps like one-hot encoding. This reduces dimensionality, prevents target leakage, and often improves model stability. However, performance ultimately depends on the specific dataset and problem type.
Does CatBoost require feature scaling?
No, CatBoost does not require feature scaling. Like other tree-based algorithms, it is insensitive to the scale of numerical features. Since decision trees split based on threshold values rather than distance metrics, normalization or standardization is generally unnecessary.
Can CatBoost handle missing values?
Yes, CatBoost automatically handles missing values during training. It treats missing values as a separate category or determines optimal splitting behavior internally. This built-in capability reduces preprocessing complexity and improves robustness in real-world datasets where missing data is common.
Is CatBoost suitable for large datasets?
Yes, CatBoost is well-suited for large datasets. It supports both CPU and GPU training, allowing it to scale efficiently. GPU acceleration significantly reduces training time when working with high-dimensional data or a large number of boosting iterations. This makes CatBoost practical for enterprise-level machine learning systems.
What types of problems can CatBoost solve?
CatBoost is a versatile algorithm that supports multiple machine learning tasks, including:
- Regression – Predicting continuous numerical values
- Binary Classification – Predicting two classes (e.g., churn vs. no churn)
- Multi-Class Classification – Predicting multiple categories
- Ranking Problems – Learning-to-rank tasks such as search result ranking
Its flexibility and strong performance across these tasks make it a comprehensive solution for structured data modeling.







