
What is k-Nearest Neighbors (k-NN)?
A supervised learning approach for classification and regression problems is called k-Nearest Neighbors (k-NN). Since it is instance-based and non-parametric, it does not explicitly learn a model during training and does not assume anything about the distribution of the data. Rather, it saves all training data and uses the similarity between data points to generate predictions.
Similar data points are found near one another in the feature space, according to the fundamental tenet of k-NN. The technique locates the k nearest neighbors in the training dataset when a new data point needs to be predicted or classed. The output is then based on the average of the neighbors’ values (for regression) or the majority class (for classification). Key Characteristics of k-NN are,
- Lazy Learning: This method memorizes the training dataset rather than creating a model during training.
- Distance-Based: A similarity metric, usually Euclidean distance, is used to make predictions.
- Easy and Effective: It performs best with well-separated classes and small datasets.
- Computationally intensive: It can be slow with large datasets because each prediction necessitates storing and searching the full dataset.
Example Use Case, To determine whether a new email is spam or not, k-NN will:
- Examine the new email against the ones that are saved in the dataset.
- Using word use, determine which k emails are the most similar.
- Give the new email the majority category (spam or not).
As a result, k-NN is frequently utilized in fields where similarity-based decision-making is helpful, such as image identification, recommendation systems, and medical diagnosis.
Introduction of k-Nearest Neighbors (k-NN)
One of the most straightforward and popular machine learning techniques for classification and regression problems is k-Nearest Neighbors (k-NN). It is a slow, instance-based, non-parametric learning method that bases its predictions on similarity metrics. K-NN does not create an explicit model, in contrast to conventional machine learning models that discover patterns in training data. Rather, it uses the k nearest data points in the feature space to generate predictions after storing the complete training dataset. Distance measurements like these are typically used to quantify how similar data points are to one another:
- Euclidean Distance (most commonly used)
- Manhattan Distance
- Minkowski Distance
- Hamming Distance (used for categorical data)
How k-NN Works?
- A fresh data point is provided for regression or categorization.
- The distance between this new point and every training data point is determined by the algorithm.
- The shortest distance values, or k nearest neighbors, are chosen.
- For classification: A majority vote among the k neighbors determines the class designation.
- For regression, the average of the values of the k neighbors is used to calculate the predicted value.
Why is k-NN Important?
- It doesn’t require intricate mathematical modeling and is simple to apply.
- Performs effectively in cases where similarity serves as the basis for relationships between data items.
- It is adaptable and capable of handling situations involving both regression and classification.
However, because k-NN needs to compute distances for each prediction, it can be computationally costly for large datasets. For speedier neighbor searching, methods such as KD-Trees and Ball Trees can be employed to maximize performance.
Detailed k-Nearest Neighbors (k-NN) Algorithm
A supervised learning approach for regression and classification is called k-Nearest Neighbors (k-NN). It makes predictions by identifying the data points that are nearest to a given input, or its neighbors. The algorithm is explained in detail below. Step-by-Step Explanation of k-NN Algorithm are,
Step 1: Select the Number of Neighbors (k)
- Choose an appropriate value for k (the number of nearest neighbors).
- A small k (e.g., k = 1 or 3) may lead to a highly sensitive model with high variance (overfitting).
- A large k (e.g., k = 10 or 20) smooths the decision boundary but may increase bias (underfitting).
- A commonly used method is to choose k = √N, where N is the number of training samples.
Step 2: Compute the Distance Between the New Data Point and All Training Data Points
We must determine the distance between each point in the training dataset and the new point in order to get the k-nearest neighbors. The distance measures that are most frequently employed are:
1. Euclidean Distance (Default Distance Metric)
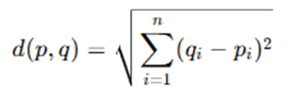
where:
- p and q are two data points in n-dimensional space.
- qi and pi are individual feature values.
- It measures the straight-line distance between two points.
2. Manhattan Distance (For Grid-Like Data)
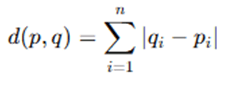
- It is used when movement is restricted to horizontal and vertical directions, such as in city block layouts.
3. Minkowski Distance (Generalized Distance Formula)
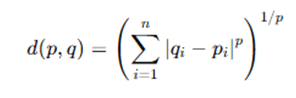
- When p = 1, it becomes Manhattan Distance.
- When p = 2, it becomes Euclidean Distance.
4. Hamming Distance (For Categorical Data)
- It counts the number of positions where two categorical strings differ.
- Used for text-based or binary classification problems.
Step 3: Identify the k Nearest Neighbors
- Sort all training samples by their computed distances from the new data point.
- Select the top k smallest distances to find the nearest neighbors.
Step 4: Make a Prediction
For Classification:
- Each of the k neighbors belongs to a class.
- Use majority voting to assign the most frequent class label among the k neighbors.
- If there’s a tie, decrease k or use a weighted voting scheme (where closer neighbors have higher weights).
Example: If k = 5, and the neighbors’ classes are:
- 3 instances of Class A
- 2 instances of Class B
Then, the new data point is classified as Class A.
For Regression: Compute the average of the k neighbors’ values to predict a continuous output.
Example: If k = 4, and the neighbors’ values are: 10, 12, 15, and 14, the predicted value is:
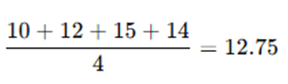
- Alternatively, we can use weighted averaging, where closer points have more influence:
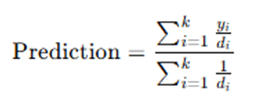
where yi is the target value and di is the distance of neighbor i.
Step 5: Evaluate Model Performance
To check how well the k-NN algorithm performs, we use evaluation metrics such as:
- For Classification, Accuracy, Precision, Recall, F1-score and Confusion Matrix
- For Regression, Mean Squared Error (MSE) and Mean Absolute Error (MAE)
Example of k-NN Classification,
We have a dataset of fruits with features like weight and color, and we want to classify a new fruit as either an Apple or Orange.
| Weight (grams) | Color (Red=1, Orange=0) | Fruit Type |
| 150 | 1 | Apple |
| 180 | 1 | Apple |
| 170 | 0 | Orange |
| 200 | 0 | Orange |
| 175 | 1 | Apple |
New Data Point:
- Weight = 185 grams
- Color = 1 (Red)
Steps:
- Compute distances between (185, 1) and all other data points using Euclidean distance.
- Select k nearest neighbors (e.g., k = 3).
- Majority vote determines the predicted class.
If the 3 nearest neighbors are (150,1), (180,1), and (175,1) → all Apples, then the new fruit is classified as Apple.
Complexity of k-NN Algorithm
- Training Time Complexity: O(1) (No explicit training, just storing data)
- Prediction Time Complexity: O(N⋅d), where N is the number of training samples and d is the feature dimensions.
- Space Complexity: O(N⋅d) (since the entire dataset is stored)
Optimizations for k-NN,
- KD-Trees and Ball Trees → Efficient nearest neighbor search.
- Dimensionality Reduction (PCA, t-SNE) → Reduces computational cost.
- Feature Scaling (Min-Max Scaling, Standardization) → Improves distance accuracy.
A straightforward yet effective technique for regression and classification is the k-NN algorithm. It doesn’t need a formal training phase and instead uses distance-based decision-making. But for big datasets, it can be computationally costly. Achieving good accuracy requires choosing the right distance metric and k value.
Advantages and Limitations of k-NN Algorithm
Despite its simplicity and efficacy, the k-Nearest Neighbors (k-NN) method has many disadvantages. We examine the main benefits and drawbacks of k-NN below.
Advantages of k-NN Algorithm
- Simple and Easy to Implement: Since k-NN directly depends on the distance between data points, it is simple to use and comprehend. It just stores the dataset and compares fresh points based on similarity; sophisticated training is not necessary.
- No Training Phase (Lazy Learning): K-NN saves the complete dataset and generates predictions as needed, as contrast to conventional machine learning models that need to be trained. Because of this, it can be applied in real-time scenarios when training is not practical.
- Effective for Small Datasets: Small datasets with low processing costs are ideal for k-NN. In these situations, it frequently outperforms more intricate models.
- Non-Parametric Nature: k-NN is very versatile because it does not presuppose any particular underlying data distribution, such as a normal distribution. When working with intricate, non-linear decision limits, this is helpful.
- Versatile (Works for Classification and Regression) k-NN can be used for both classification (categorical labels) and regression (continuous values) problems. Example: Classification: Identifying spam emails. Regression: Predicting house prices.
- Handles Multi-Class Classification Well: Unlike many models that are solely intended for binary classification, k-NN is able to classify into numerous categories via majority voting.
- Works with Any Distance Metric: k-NN is flexible enough to work with a variety of data types since it can employ several distance metrics, including Euclidean, Manhattan, Minkowski, or Hamming distance.
Limitations of k-NN Algorithm
- Computationally Expensive for Large Datasets: k-NN requires storing and comparing each new data point with the entire training dataset, leading to: High memory consumption Slow prediction times for large datasets. Example: If the dataset has 1 million data points, computing distances for every new query can be very slow.
- Sensitive to Irrelevant or Redundant Features: If the dataset has many irrelevant features, they can reduce the accuracy of k-NN. Solution: Feature selection or dimensionality reduction techniques like Principal Component Analysis (PCA).
- Curse of Dimensionality: As the number of features (dimensions) increases, the distance between points becomes less meaningful, leading to poor performance. Solution: Use feature selection techniques to reduce dimensionality.
- Imbalanced Data Can Bias Predictions: If one class is significantly more frequent than others, k-NN might favor that class in classification tasks. Solution: Balance the dataset using oversampling (SMOTE) or undersampling techniques.
- Choosing the Right Value of k is Crucial: A small k (e.g., k=1 or 3) makes k-NN highly sensitive to noise, leading to overfitting. A large k (e.g., k=20 or 50) smooths decision boundaries but may cause underfitting. Solution: Use cross-validation to find the optimal k.
- Not Suitable for Real-Time Predictions in Large Datasets: Since k-NN stores the entire dataset, real-time queries require scanning all data points, making it impractical for high-speed applications.
- Performance Decreases with High Variance Data : k-NN is sensitive to noisy data, leading to incorrect classifications if outliers are present. Solution: Use distance weighting (giving closer points more influence) or preprocess data to remove noise.
| Advantages | Limitations |
| Simple and easy to understand | Computationally expensive for large datasets |
| No training phase (lazy learning) | Sensitive to irrelevant or redundant features |
| Works well with small datasets | Suffers from the curse of dimensionality |
| No assumptions about data distribution | Imbalanced data affects classification accuracy |
| Effective for both classification and regression | Choosing the right k is difficult |
| Handles multi-class classification | Slow real-time predictions in large datasets |
| Can use various distance metrics | Affected by high variance and noisy data |
In strong and user-friendly machine learning technique for regression and classification is the k-NN algorithm. The curse of dimensionality, sensitivity to unimportant features, and high computing cost are some of its drawbacks. These restrictions can be lessened by choosing the appropriate k value, refining distance measurements, and utilizing feature selection strategies, which makes k-NN a compelling option for a variety of machine learning applications.
Applications of k-NN Algorithm
Because of its ease of use, efficiency, and adaptability, the k-Nearest Neighbors (k-NN) method is frequently applied in many different fields. It is helpful in many real-world situations because it can be applied to both classification and regression problems.
- Image Recognition and Computer Vision: k-NN is commonly used in image classification, object detection, and facial recognition by comparing pixel intensities or feature embeddings. For example, in handwritten digit recognition using the MNIST dataset, k-NN classifies images based on pixel similarity. A real-world use case is Facebook’s face recognition system, which employs k-NN to identify people in photos.
- Recommender Systems: k-NN is widely applied in recommendation engines to suggest products, movies, or songs based on user preferences. For instance, in e-commerce platforms like Amazon, Flipkart, and eBay, it suggests similar products based on user purchase history. On streaming platforms such as Netflix, Spotify, and YouTube, it recommends content aligned with user interests.
- Medical Diagnosis and Healthcare: k-NN plays a vital role in disease prediction, patient classification, and medical image analysis by comparing new patient data with historical cases. It is used, for example, to predict whether a tumor is benign or malignant, and to diagnose conditions like diabetes or heart disease. A real-world application includes breast cancer detection via mammogram analysis.
- Fraud Detection in Banking and Finance: In financial security, k-NN is utilized to detect fraudulent transactions by identifying anomalies in user behavior. For example, if a user who typically makes small purchases suddenly initiates a large international transaction, k-NN can flag it as suspicious. It is used by institutions like JPMorgan, HSBC, and PayPal for fraud prevention.
- Text Classification and Spam Filtering: k-NN aids in tasks like email spam detection, sentiment analysis, and document classification by examining word frequencies and patterns. For instance, it is employed in Gmail and Outlook to classify emails as spam or not, and in platforms like Google News and Yahoo News to categorize news articles by topic.
- Customer Segmentation and Targeted Marketing: Marketers use k-NN for customer profiling, market analysis, and personalized advertising. E-commerce websites analyze purchase history to suggest similar products, while marketers segment customers based on age, location, and shopping behavior. Companies such as Amazon, Flipkart, and Facebook Ads leverage k-NN for personalized targeting.
- Stock Market Prediction and Financial Forecasting: k-NN helps predict stock prices by comparing current market conditions with historical trends. For instance, it may be used to forecast future stock prices or classify stocks as “risky” or “safe” based on earnings reports. Bloomberg, Reuters, and various hedge funds apply k-NN in financial analytics.
- Anomaly Detection and Cybersecurity: k-NN is valuable in identifying cyber threats, network intrusions, and system anomalies. It can detect DDoS attacks by recognizing unusual traffic spikes or identify malware by comparing files to known threats. Intrusion detection systems like Snort and Suricata use k-NN for cybersecurity.
- Speech Recognition and Natural Language Processing (NLP): k-NN is used in voice recognition, chatbots, and NLP applications to classify spoken or written input. Examples include virtual assistants like Siri, Alexa, and Google Assistant recognizing user intent, and customer support chatbots categorizing user queries.
- Agriculture and Weather Prediction: In agriculture, k-NN is used for crop classification, soil fertility prediction, and weather forecasting. It can classify crops based on soil conditions and historical data or predict rainfall using climate patterns. Agricultural research organizations use k-NN to support data-driven farming decisions.
One effective and adaptable machine learning method that is utilized in many different industries is the k-Nearest Neighbors (k-NN) algorithm. Where similarity-based decision-making is required, k-NN offers efficient solutions in fields ranging from image recognition and healthcare to finance and cybersecurity. However, feature selection, dataset size, and computational optimizations all affect how effective it is.
Conclusion
For classification and regression applications, the k-Nearest Neighbors (k-NN) algorithm is a straightforward yet effective supervised learning technique. Its instance-based learning methodology, which depends on data point similarity rather than training, gives it great flexibility. Image identification, recommendation systems, medical diagnosis, fraud detection, and natural language processing are just a few of the many applications where k-NN excels. Appropriate feature selection, distance metrics, and the number of neighbors (k) are all necessary for its efficacy. Notwithstanding its benefits, k-NN has drawbacks, including the curse of dimensionality, sensitivity to unimportant features, and a high processing cost for large datasets. By employing methods like dimensionality reduction (PCA), KD-trees, and ball trees to expedite nearest-neighbor searches, these problems can be lessened. Additionally, cross-validation optimization of k guarantees improved model performance.
In conclusion, because of its ease of use, adaptability, and efficiency, k-NN is still a crucial method in machine learning. Small to medium-sized datasets with well-structured features are its ideal fit. Optimizations or other machine learning models, like decision trees, support vector machines (SVM), or deep learning, might be more effective for large-scale applications.
Frequently Asked Questions (FAQs)
Q1. How does the k-Nearest Neighbors (k-NN) algorithm work?
A supervised learning approach called k-NN uses the majority class of the training dataset’s k closest neighbors to categorize fresh data points. It chooses the k nearest neighbors, determines the distance (such as Manhattan or Euclidean) between the new point and every training point, and either assigns the most common class (for classification) or takes the average (for regression).
Q2. How do you choose the optimal value of k in k-NN?
The model’s performance is strongly impacted by the value of k. While a large k (such as k=20 or 50) may result in underfitting, a little k (such as k=1 or 3) may result in overfitting. Choosing k = √N, where N is the total number of training samples, is a popular method. An additional technique for identifying the optimal k-value is cross-validation.
Q3. What are the main advantages and disadvantages of k-NN?
Advantages:
- Easy to use and straightforward.
- It is perfect for real-time applications because it doesn’t require a training phase and performs well on both classification and regression tasks.
Disadvantages:
- Sensitive to high-dimensional data and unimportant features (curse of dimensionality); computationally costly for large datasets.
- For precise distance computations, appropriate feature scaling (such as normalization or standardization) is necessary.
Q4. What are some common applications of k-NN?
k-NN is widely used in:
- Image recognition (e.g., classification of handwritten digits in the MNIST dataset).
- Recommendation engines (such as those that suggest movies and products).
- Medical diagnostics, such as the identification of cancer from patient information.
- Banking fraud detection, such as spotting questionable transactions.
- Text classification and spam filtering.
Q5. How can k-NN be optimized for large datasets?
For large datasets, k-NN can be slow because it needs to store and search the full dataset. Among the optimization methods are:
- To expedite the nearest neighbor search, use data structures like Ball Trees or KD-Trees.
- Using dimensionality reduction methods to lower computing cost, such as PCA and t-SNE.
- To cut down on query time, use approximate nearest neighbor (ANN) search techniques.
For extensive machine learning applications, these enhancements contribute to k-NN’s increased efficiency.









