
What is MobileNet (MobileNetV1, V2, V3)
Google created the MobileNet family of lightweight, effective convolutional neural network (CNN) architectures for embedded and mobile vision applications. MobileNet models’ primary objective is to provide high accuracy while reducing memory and computational costs, which makes them perfect for real-time applications on low-resource devices.
- MobileNetV1 (2017): Introduced the idea of depthwise separable convolutions, which divide a conventional convolution into two easier steps: Depthwise convolution: uses one filter for every channel of input. By combining the outputs from the depthwise step, pointwise convolution (1×1) significantly lowers the computational effort and parameter count.
- MobileNetV2 (2018): Based on V1, it introduced two significant innovations: Skip connections between bottleneck layers are used in inverted residuals. In order to preserve information, linear bottlenecks steer clear of non-linearities (such as ReLU) at the output of bottleneck layers. These enhancements facilitate more effective training and inference and enhance feature representation.
- MobileNetV3 (2019): Utilizes squeeze-and-excitation (SE) blocks for channel-wise attention in conjunction with the architectural advantages of V1 and V2. Hard-Swish activation function for more affordable and superior nonlinear modeling: Using neural architecture search (NAS), ideal structures are automatically designed. Available in two versions: MobileNetV3-Large (for accuracy) and MobileNetV3-Small (for speed).
In the MobileNetV1, V2, and V3 are excellent choices for mobile, embedded, and real-time AI applications because they gradually enhance the trade-off between model size, speed, and accuracy.
Introduction of MobileNet (MobileNetV1, V2, V3)
The MobileNet family is a significant advancement in the creation of accurate and efficient deep learning models, especially for deployment on edge devices, embedded systems, and mobile devices with constrained computational resources.
Why MobileNet Was Introduced?
Conventional convolutional neural networks (CNNs), such as VGG or ResNet, are large, computationally demanding, and dependent on expensive GPUs or cloud infrastructure. Because of these features, they are not appropriate for use in AR/VR systems, drones, IoT devices, or mobile apps where real-time computing, low latency, and low battery consumption are essential. Google researchers created MobileNet, an architecture that aims to decrease the following issues: • Model size (number of parameters); • Computational complexity (FLOPs); and • Inference time (delay).
B. Evolution of the MobileNet Algorithm
MobileNetV1 (2017):
- Introduced depthwise separable convolutions, reducing computation by nearly 90% compared to standard convolutions.
- Used two parameters:
- Width multiplier (α): reduces the number of channels.
- Resolution multiplier (ρ): reduces input image resolution.
C. MobileNetV2 (2018):
- Addressed the loss of feature richness in V1 by introducing:
- Inverted residual blocks: helps in better gradient flow and reusability of features.
- Linear bottlenecks: avoids loss of information due to activation functions at bottleneck outputs.
- Improved performance without significantly increasing model size.
D. MobileNetV3 (2019):
- Designed using Neural Architecture Search (NAS) to find the most efficient model blocks.
- Included:
- Squeeze-and-Excite (SE) modules: for channel attention.
- Hard-Swish activation: a lightweight alternative to Swish activation.
- Offered two versions:
- MobileNetV3-Small (for mobile-speed optimization)
- MobileNetV3-Large (for accuracy-critical tasks)
In brief a progression in architectural design for efficiency is demonstrated by MobileNetV1, V2, and V3, guaranteeing that deep learning may be employed successfully in resource-constrained contexts without significantly compromising accuracy. These models are increasingly frequently seen in autonomous systems, smart cameras, smartphone apps, and other applications.
Detailed MobileNet (MobileNetV1, V2, V3)
The MobileNet models are designed to be computationally efficient while maintaining high accuracy. Each version introduces novel architectural improvements. Below is a breakdown of the key algorithms and formulas used in MobileNetV1, V2, and V3, explained step by step.
- MobileNetV1: Depthwise Separable Convolutions
Replace standard convolutions with depthwise separable convolutions to reduce computational cost.
Standard Convolution: For an input with shape DF×DF×M, and a convolution layer with N filters of size DK×DK the cost is:
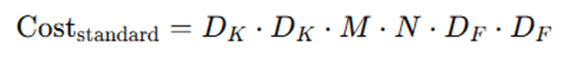
Depthwise Separable Convolution: Split into two parts:
- Depthwise Convolution – Applies one filter per input channel:
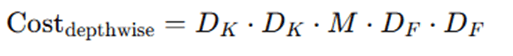
Pointwise Convolution – 1×1 convolution to mix channels:
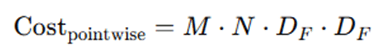
Total Cost Reduction:
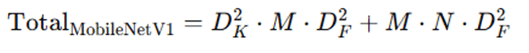
This results in ~8 to 9 times fewer computations than standard convolutions.
- MobileNetV2: Inverted Residuals and Linear Bottlenecks
Key Innovations:
- Inverted residuals: Expand → depthwise → project (compress).
- Linear bottleneck: No non-linearity (like ReLU) at the projection layer.
Inverted Residual Block Structure:
- Expansion Layer:

Expands the channels.
- Depthwise Convolution:

- Projection (Linear Bottleneck):

- Skip Connection (if input and output dimensions match):
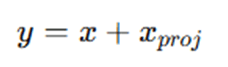
Intuition:
- Expanding the feature space before applying depthwise convolution allows better feature extraction.
- Linear bottleneck helps preserve information.
C.MobileNetV3: NAS + SE + Hard-Swish
Key Enhancements:
- Neural Architecture Search (NAS): Automatically selects efficient layer combinations.
- Squeeze-and-Excitation (SE) blocks: Add channel-wise attention.
- Hard-Swish Activation: Efficient and effective nonlinear function.
Squeeze-and-Excitation (SE) Block:
- Squeeze: Global average pooling on each channel:
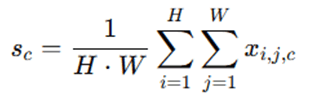
- Excite: Fully connected layers + sigmoid:

- Scale Input:
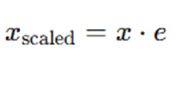
Hard-Swish Activation:
Efficient alternative to Swish:
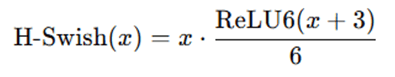
It approximates the performance of Swish while being faster to compute.
MobileNetV3 Block Summary:
Each block consists of:
- Expansion (using 1×1 conv + H-Swish or ReLU)
- Depthwise convolution (with optional SE)
- Projection (linear 1×1 conv)
- Skip connection if dimensions allow
Comparison Table
| Feature | MobileNetV1 | MobileNetV2 | MobileNetV3 |
| Convolution Type | Depthwise Separable | Depthwise + Inverted Residual | NAS-optimized blocks + SE + H-Swish |
| Activation | ReLU6 | ReLU6 | ReLU6 / Hard-Swish |
| Feature Enhancement | – | Inverted residuals, bottlenecks | SE Modules, NAS |
| Performance | Efficient | More accurate than V1 | Best balance of speed and accuracy |
Advantages and Limitations of MobileNet
Advantages
- Lightweight and Efficient: MobileNet is specifically designed for resource-constrained environments like mobile phones, IoT devices, and embedded systems. It has a small model size and low memory footprint, making it easy to deploy on edge devices.
- Faster Inference: Thanks to its use of depthwise separable convolutions, MobileNet significantly reduces the number of parameters and computation time compared to traditional convolutional neural networks like VGG or ResNet. This leads to real-time performance on mobile CPUs and GPUs.
- Customizable (Width and Resolution Multipliers): MobileNet offers scaling parameters like:Width multiplier (α): Reduces the number of channels.Resolution multiplier (ρ): Reduces input image size.
These hyperparameters allow developers to trade off accuracy for speed and size based on the deployment need. - Good Accuracy vs. Efficiency Trade-off: Despite being lightweight, MobileNet provides competitive accuracy on tasks like image classification, object detection, and face recognition, especially when compared to similarly small models.
- Transfer Learning Friendly: MobileNet models are widely used as feature extractors in transfer learning scenarios. They integrate easily into frameworks like TensorFlow and PyTorch, and pretrained weights are readily available.
- Broad Deployment Support: MobileNet is supported in popular machine learningtoolkits and mobile-focused platforms like TensorFlow Lite, CoreML, and ONNX, making it practical for cross-platform applications.
Disadvantages
- Lower Accuracy than Larger Models: While efficient, MobileNet typically performs worse than deeper models like ResNet, Inception, or EfficientNet in terms of accuracy, especially on more complex datasets or tasks that require fine-grained features.
- Limited Learning Capacity: Because of its shallow and narrow architecture (for speed), MobileNet may underfit complex datasets or fail to capture detailed patterns needed for high-level recognition tasks.
- Sensitive to Quantization: Although MobileNet can be quantized for deployment (e.g., INT8), aggressive quantization may lead to accuracy degradation, especially for older versions like MobileNetV1.
- Architecture Optimization is Task-Specific: MobileNet needs to be tuned for specific tasks and devices. The optimal setting of width and resolution multipliers varies, and suboptimal settings can result in poor accuracy or slow performance.
- Not Ideal for All Use Cases: For large-scale training, multi-object detection, or very high-resolution inputs, MobileNet may lack the representational power required, and more robust models (like EfficientNet or YOLOv7) may be preferred.
Applications of MobileNet
MobileNet algorithms are perfect for a variety of applications on mobile, embedded, and edge devices since they are specifically built to allow high-performance deep learning in real-time, resource-constrained contexts. Some of the most popular and significant MobileNetV1, V2, and V3 use cases are listed below:
- Classification of Images in Real Time on Mobile Devices: Mobile apps frequently employ MobileNet models to categorize photos on-site without the need for cloud processing. This protects user privacy and allows for quicker responses.
- Embedded System Object Detection : Lightweight object recognition frameworks like YOLO (You Only Look Once) and SSD (Single Shot MultiBox Detector) frequently employ MobileNet as its foundation. For real-time tracking and detection, these are used in systems such as smart home appliances, surveillance cameras, and drones.
- Face Landmark Detection and Recognition : MobileNet models’ low latency and high accuracy make them perfect for emotion detection software, access control systems, and smartphone facial recognition systems (like face unlock).
- Virtual reality (VR) and augmented reality (AR) : AR/VR apps may now process visual data in real time thanks to MobileNet, which improves responsiveness and smoothness of interaction on devices with low processing power.
- Pose and Gesture Recognition : MobileNet is used as a feature extractor in lightweight pose estimation models to identify human movements and postures, which are helpful in gaming interfaces, fitness tracking, and sign language interpretation.
- Drones and Robots with Autonomous Navigation : MobileNets are appropriate for on-device visual perception tasks in robotics, including path planning, obstacle avoidance, and environmental mapping, because of their speed and low power consumption.
- Edge Devices for Medical Imaging : For rapid diagnostic tasks like identifying skin lesions, detecting pneumonia in chest X-rays, or categorizing retinal scans, MobileNet can be implemented in portable medical devices.
- Inventory and Retail Management : MobileNet enables automation and efficiency in smart retail systems by being utilized for barcode-less checkout procedures, shelf monitoring, and visual product recognition.
In all these applications, MobileNet’s ability to deliver real-time performance with minimal computational demands makes it a preferred choice for deploying AI solutions on devices where size, speed, and power consumption are critical.
Conclusion
The creation of effective and scalable deep learning models for mobile and embedded applications has advanced significantly with the MobileNet family, which includes MobileNetV1, V2, and V3. Every iteration improves on the one before it by offering novel methods for lowering computational complexity and model size while maintaining or even improving performance. In order to significantly reduce the number of parameters and processes, MobileNetV1 was the first to employ depthwise separable convolutions. By introducing the ideas of linear bottlenecks and inverted residuals, MobileNetV2 improved gradient flow and feature representation. By including Squeeze-and-Excitation modules, Hard-Swish activation, and using Neural Architecture Search to automate design enhancements, MobileNetV3 went one step further.
When combined, these architectures enable developers to introduce potent AI capabilities to hardware-constrained devices, enabling applications ranging from facial recognition and augmented reality to real-time image classification and object identification. Traditional CNNs are frequently too heavy to use in edge computing applications, where the models’ accuracy, speed, and flexibility make them perfect. MobileNet continues to be a fundamental architecture as AI advances toward on-device intelligence, weighing the trade-offs between efficiency and performance for practical application.
Frequently Asked Questions (FAQs)
Q1. What makes MobileNet different from traditional CNNs like VGG or ResNet?
Answer: In order to dramatically minimize the amount of parameters and computational operations, MobileNet uses techniques such as depthwise separable convolutions. In contrast to standard CNNs, which are usually big and resource-intensive, this makes it appropriate for real-time applications on mobile and embedded devices.
Q2. What are the key improvements in MobileNetV2 over MobileNetV1?
Answer: Better feature representation, more training stability, and less information loss are made possible by MobileNetV2’s introduction of inverted residual blocks and linear bottlenecks. These developments enable the model to stay lightweight while maintaining accuracy.
Q3. Why is MobileNetV3 considered more advanced than its predecessors?
Answer: In addition to features like Squeeze-and-Excitation (SE) blocks for channel attention and the Hard-Swish activation function for computational efficiency, MobileNetV3 incorporates Neural Architecture Search (NAS) to optimize the model structure. Both speed and accuracy are increased by these improvements.
Q4. Can MobileNet models be used for tasks other than image classification?
Answer: Indeed, MobileNet provides a flexible foundation for a range of computer vision applications since it may be utilized as a feature extractor in additional tasks including object identification (e.g., using SSD), semantic segmentation, face recognition, and even posture estimation.
Q5. How do I choose between MobileNetV1, V2, and V3 for my application?
Answer: MobileNetV1 can be adequate if speed and small size are the top priorities for your application. While MobileNetV3 offers the best trade-off between speed, accuracy, and resource utilization, MobileNetV2 combines superior accuracy with more efficient performance. The hardware limitations of your device and the difficulty of your assignment should guide your decision.









