
What is Autoencoders (AE) Algorithm?
An Artificial Neural Network type called an Autoencoder (AE) is used for unsupervised learning. Its objective is to learn effective data representations, usually for feature learning or dimensionality reduction. There are two primary parts of an autoencoder:
- Encoder: This network component compresses the input data into an encoded representation, also referred to as the latent space. The input is converted into a compact code by the encoder.
- Decoder: Using the encoded representation, the decoder tries to recreate the original input. Reducing the disparity between the input data and the reconstructed result is the aim.
Reconstruction error, or the difference between input and output, is minimized in order to train the autoencoder. By doing this, the model gains the ability to identify the most significant aspects of the incoming data while eliminating extraneous information and noise.
In order to be useful for tasks like anomaly detection, denoising, or even creating new data that is comparable to the original dataset, an autoencoder usually aims to learn a compressed, lower-dimensional representation of the input data that captures the important patterns and structures.
Introduction of Autoencoders (AE) Algorithm
The goal of unsupervised learning tasks involving autoencoders (AE), a form of artificial neural network, is to learn effective representations of input data in a lower-dimensional space. Data compression, feature extraction, and dimensionality reduction are common applications for the autoencoder algorithm. Because it does not require labeled input for training, it is especially effective in applications where labeled data is limited. The basic structure of an autoencoder consists of two main components:
- Encoder: This component is in charge of condensing the input data into a more manageable, compact representation. It turns the original data into a concealed layer that highlights its salient characteristics.
- Decoder: Using the compact encoded form, the decoder reconstructs the input data. In order to minimize the loss between the input and the reconstructed data, the goal is to reconstruct the input as precisely as feasible.
Key Concepts:
- Latent Space (Code): The autoencoder’s key component is the compressed representation of the input data, also known as the latent space or code. By removing unnecessary features, this lower-dimensional encoding keeps the most important information from the input.
- Reconstruction Error: The autoencoder’s quality is based on how well the decoder can use the latent code to reconstruct the original input. The network is trained to minimize the reconstruction error, which is a measure of this difference (e.g., Mean Squared Error).
Training Procedure: Autoencoders are trained by using a loss function to minimize the difference between the input and the output (reconstructed data). Depending on the purpose and type of data, many loss functions may be employed, however Mean Squared Error (MSE) is the most often utilized. Usually, backpropagation and optimization methods like gradient descent are used to train the model.
Types of Autoencoders:
- Vanilla Autoencoder: The basic version with a simple encoder-decoder structure.
- Denoising Autoencoder (DAE): Designed to remove noise from input data by training the model to reconstruct the clean data from noisy versions.
- Variational Autoencoder (VAE): A probabilistic version of autoencoders that provides a more structured latent space for generating new data points.
- Sparse Autoencoder: Introduces a sparsity constraint on the encoder’s hidden layer, forcing it to learn a compact and sparse representation.
Overall, autoencoders are an essential tool in unsupervised learning, providing an effective way to learn compact and meaningful representations of data.
Detailed Autoencoders (AE) Algorithm
The Autoencoders (AE) algorithm consists of two main components: the encoder and the decoder, which work together to compress the input data into a latent space and then reconstruct it. Here’s a detailed step-by-step breakdown of the algorithm, including relevant formulas:
Step 1: Input Data
- Input: Let the input data be represented as X∈Rn, where n is the number of features or dimensions in the input data. Each sample in the input is a vector in this space.
Step 2: Encoder – Compression of Input Data
- The encoder takes the input X and maps it to a latent (compressed) representation hhh. This is done using a neural network or a set of transformations.
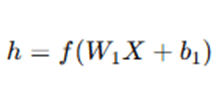
where:
- W1 is the weight matrix for the encoder,
- b1 is the bias vector for the encoder,
- f is the activation function (e.g., ReLU, sigmoid, or tanh) applied to the linear transformation.
Here, the encoder is learning to reduce the input X into a compressed vector h, which contains the most essential features of the data.
Step 3: Latent Space Representation
- The output of the encoder, h, is the latent space or code. This is a lower-dimensional representation of the original input. The size of this latent space (dimensionality) is typically smaller than the original input space.
The goal of this latent space is to preserve the important features of the input data while discarding irrelevant information.
Step 4: Decoder – Reconstruction of Input Data
- The decoder takes the latent representation h and reconstructs the original input X. The decoder tries to map the latent code h back to the original input space.
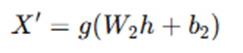
where:
- W2 is the weight matrix for the decoder,
- b2 is the bias vector for the decoder,
- g is the activation function applied to the output layer (e.g., sigmoid or linear, depending on the type of data).
The decoder aims to approximate the input X from the encoded representation h. The output X′ is the reconstructed version of X.
Step 5: Loss Function (Reconstruction Error)
- The performance of the autoencoder is evaluated based on how well the decoder can reconstruct the input from the encoded representation. The loss function is used to measure the reconstruction error.
- Common loss functions:
- Mean Squared Error (MSE):
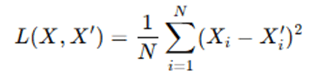
where N is the number of features, Xi is the i-th element of the original input, and Xi′ is the i-th element of the reconstructed input.
- Binary Cross-Entropy (for binary data or normalized input):
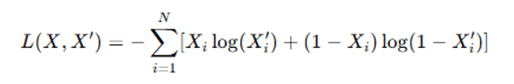
- The objective is to minimize the loss function, which measures the discrepancy between the original input X and the reconstructed input X′.
Step 6: Optimization (Training the Autoencoder)
- The training process uses backpropagation and gradient descent to update the weights W1, W2 and biases b1,b2 in order to minimize the reconstruction error (the loss function).
- Gradient Descent Update:
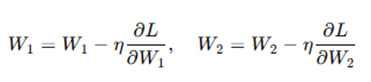
where η is the learning rate, and
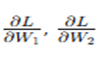
are the gradients of the loss with respect to the encoder and decoder weights, respectively.
- The weights and biases are adjusted iteratively until the loss function converges to a minimum, meaning that the network has learned an efficient representation of the input data.
Step 7: Final Output
- After training, the encoder can be used to compress new input data into its latent representation, and the decoder can reconstruct data from this latent representation.
- The learned encoder-decoder model can be applied for various tasks such as data compression, anomaly detection, and denoising.
In essence, the autoencoder learns to map the input data to a compact representation and then reconstruct it, optimizing the network to preserve as much important information as possible while minimizing the reconstruction error.
Advantages and Disadvantages of Autoencoders (AE)
Advantages
- Unsupervised Learning: AEs do not require labeled data—they learn patterns and compress information purely from the input data.
- Nonlinear Dimensionality Reduction: Unlike PCA, autoencoders can capture nonlinear relationships in the data, enabling more powerful feature extraction.
- Noise Robustness (Denoising Autoencoders): Variants like denoising autoencoders can learn to recover clean data from corrupted inputs, useful in preprocessing and image restoration.
- Customizable Architecture: You can tailor the network (e.g., convolutional, recurrent, variational) to suit different data types like images, sequences, or time series.
- Anomaly Detection: AEs are effective for detecting outliers by measuring reconstruction error—useful in cybersecurity, fraud detection, and predictive maintenance.
- Data Compression: Encoded (latent) representations can be used for data compression, reducing storage or transmission costs.
- Foundation for Generative Models: AEs are foundational for Variational Autoencoders (VAEs) and Adversarial Autoencoders, which are popular in generative modeling.
Disadvantages
- Overfitting Risk: If not regularized or trained properly, AEs may simply memorize input data instead of learning meaningful representations.
- No Guarantee of Meaningful Latent Space: Basic AEs don’t ensure that the encoded (latent) space has structure or interpretability—unlike VAEs.
- Sensitive to Architecture Choices: Performance depends heavily on the size of the hidden layers, activation functions, and other design choices.
- Require Large Datasets: For deep or complex architectures, AEs need a large amount of training data to learn generalizable representations.
- Computationally Intensive: Training deep autoencoders, especially with large inputs (e.g., high-resolution images), can be computationally expensive.
- Non-Probabilistic (Basic AE): Unlike probabilistic models like VAEs, standard AEs do not model uncertainty, making them less useful for generative tasks.
- Reconstruction Not Always Meaningful: AEs optimize reconstruction loss, which doesn’t always lead to human-interpretable or semantically useful features.
Applications of Autoencoders (AE) Algorithm
Autoencoders are powerful unsupervised learning algorithms used for a wide range of tasks across various domains. Their ability to learn compressed, meaningful representations of data makes them useful in fields such as anomaly detection, data denoising, and even generative modeling. Below is a detailed look at some of the most impactful applications of autoencoders.
- Anomaly Detection: One of the most prominent applications of autoencoders is in anomaly detection, where the goal is to identify rare or unusual events in data that deviate from the norm. Autoencoders are trained on normal data so they learn to reconstruct it with low error. When an anomalous input is presented, the reconstruction error becomes significantly higher, signaling the presence of an anomaly. This technique is widely used in cybersecurity for detecting network intrusions, in manufacturing for identifying equipment malfunctions, and in financial systems for spotting fraudulent transactions. The unsupervised nature of autoencoders makes them especially useful in scenarios where anomalies are rare or not labeled.
- Data Denoising: Autoencoders are also highly effective in data denoising, where the goal is to remove unwanted noise from data without losing important information. Denoising autoencoders are trained by corrupting input data with noise and teaching the model to reconstruct the original, clean version. This technique is commonly applied in image processing to remove visual noise or grain, and in audio processing to clean up background noise. For example, autoencoders can significantly enhance low-quality MRI scans or audio recordings, making them more useful for analysis or diagnostic purposes.
- Dimensionality Reduction: Autoencoders serve as a powerful nonlinear alternative to traditional methods like Principal Component Analysis (PCA) for dimensionality reduction. By encoding input data into a lower-dimensional latent space, autoencoders can compress high-dimensional features while preserving important information. This latent representation can be used for visualization, clustering, or as a preprocessing step before applying other machine learning algorithms. When visualizing complex datasets in 2D or 3D, autoencoders can retain more meaningful structures than linear methods, making them invaluable for exploratory data analysis.
- Representation Learning: Another major use of autoencoders lies in representation learning, where the goal is to discover efficient, high-level features from raw data. These features—also known as embeddings or latent variables—are learned in an unsupervised manner and can be used in downstream tasks such as classification, clustering, or reinforcement learning. In computer vision, for instance, autoencoders can be used to extract essential characteristics from images. Similarly, in natural language processing (NLP), they can capture semantic structures from textual data, making them suitable for tasks like sentiment analysis or document categorization.
- Image Generation (with Variational Autoencoders – VAEs): Autoencoders can be adapted for generative modeling using Variational Autoencoders (VAEs). VAEs not only learn to reconstruct data but also to generate new samples that resemble the original data distribution. This is done by sampling from a learned latent space that is continuous and structured. VAEs have been widely used in generating handwritten digits, human faces, and even artistic styles. These models are particularly useful in creative AI applications, data augmentation, and scenarios requiring synthetic data generation.
- Data Compression: Autoencoders are naturally suited for lossy data compression, as their architecture is designed to condense input into a smaller latent representation and then reconstruct it. This can be used to compress large datasets, such as satellite imagery, video data, or medical images, allowing for more efficient storage and faster transmission. Although the compression is not lossless, it often retains the key information needed for further processing, making it a practical tool in bandwidth-constrained or memory-limited environments.
- Recommendation Systems: In recommendation systems, autoencoders can be employed for collaborative filtering and matrix completion. By encoding user-item interaction data, autoencoders can predict missing values (e.g., what a user might like based on past behavior). This approach is used in platforms like Netflix, YouTube, or Amazon to suggest movies, products, or videos. Autoencoders excel in learning hidden patterns in sparse data matrices, making them more accurate than traditional matrix factorization methods in certain cases.
- Medical Imaging: Autoencoders play an important role in medical image analysis, where they are used to detect abnormalities in scans such as X-rays, MRIs, or CT images. Trained on healthy or typical anatomical images, autoencoders can reconstruct normal structures and highlight deviations as reconstruction errors. These anomalies may correspond to tumors, fractures, or lesions. In this way, autoencoders support diagnostic tools, assisting doctors in early detection and monitoring of diseases with minimal labeled data.
- Text Embedding & Semantic Hashing: Autoencoders can be adapted to handle text data by learning compact, dense vector representations of documents or sentences. These embeddings can then be used for semantic hashing, where similar documents are hashed to nearby codes, enabling fast and accurate information retrieval. This is particularly useful in search engines, chatbots, or document clustering systems. For example, stacked autoencoders have been used to convert long articles into numerical representations that capture their core meaning, improving the performance of search and classification tasks.
Conclusion
An effective and adaptable method for unsupervised learning, autoencoders (AE) provide a strong foundation for learning concise and significant data representations. Autoencoders are able to compress input data into a lower-dimensional latent space and recover it with little loss by employing a straightforward yet efficient encoder-decoder architecture. They are particularly helpful for applications like dimensionality reduction, denoising, anomaly detection, and feature extraction because of their capability. Deeper understanding of high-dimensional datasets is made possible by autoencoders’ ability to describe intricate, nonlinear interactions, in contrast to conventional linear approaches.
Their versatility across a wide range of domains, including image processing, cybersecurity, healthcare, and more, is further enhanced by their capacity to adapt to various data types and topologies, from simple feedforward networks to convolutional and recurrent structures. The representations that autoencoders learn, even though they are unsupervised, frequently improve the results of downstream supervised tasks. In conclusion, autoencoders are crucial parts of contemporary machine learning pipelines because of their adaptability, effectiveness, and capacity to uncover hidden patterns in data. They are not merely instruments for data compression or reconstruction.
Frequently Asked Questions (FAQs)
Q1. What is the primary purpose of an autoencoder?
Answer: An autoencoder’s primary function is to learn an efficient, compressed representation of input data without supervision. In order to recreate the original input, it first encodes the data into a latent space and then decodes it back. Data compression, feature learning, and dimensionality reduction are among the tasks that this approach aids in.
Q2. How does an autoencoder differ from other dimensionality reduction techniques like PCA?
Answer: Although PCA and autoencoders both seek to minimize the dimensionality of the data, autoencoders’ neural network-based architecture gives them the advantage of modeling nonlinear interactions. While autoencoders can learn more intricate and abstract features through deeper layers and activation functions, PCA, being a linear approach, can only capture linear relationships.
Q3. Can autoencoders be used for supervised learning tasks?
Answer: Although autoencoders are unsupervised models in and of themselves, supervised learning tasks can benefit from the latent information they pick up. The encoded representations, for instance, can be used as input features for regression or classification models, which frequently produce superior results because of the decreased dimensionality and noise.
Q4. What types of data can autoencoders handle?
Answer: Because of its great adaptability, autoencoders can be used with a wide range of data formats, such as text, audio, pictures, and time-series data. Autoencoders can efficiently learn representations appropriate for the particular structure of the input data by tailoring the architecture, for example, by employing recurrent layers for sequences or convolutional layers for images.
Q5. What are some limitations of autoencoders?
Answer: Autoencoders are not without restrictions, despite their advantages. If the model is very complicated or improperly regularized, they may overfit the training data. Additionally, the model may just memorize the input instead of learning significant features if the latent space is too big or the reconstruction goal is too simple. Furthermore, the quantity and quality of training data have a significant impact on their performance.









