
What is Gated Recurrent Unit (GRU) Algorithm?
A particular kind of Recurrent Neural Network (RNN) architecture called the Gated Recurrent Unit (GRU) is used to simulate sequential data, including speech, time series, and spoken language. In 2014, Kyunghyun Cho et al. presented GRUs as a less complicated substitute for the Long Short-Term Memory (LSTM) network. The vanishing gradient issue that typical RNNs have while learning long-range dependencies is one that GRUs, like LSTMs, are made to solve. Key Features are:
GRU presents gating units, which regulate data flow without the need for distinct memory cells.
- There are two primary gates: Update Gate: determines what data should be shared with the future. The reset gate determines how much of the past should be forgotten.
- At each time step, the hidden state in GRU updates the pertinent data from earlier steps.
In the GRU algorithm is computationally more efficient than LSTM and enables neural networks to remember or forget information intelligently across sequences, making it ideal for jobs like language modeling, translation, and time series forecasting.
Introduction of GRU Algorithm
In their 2014 study on neural machine translation, Kyunghyun Cho et al. presented the Gated Recurrent Unit (GRU) algorithm, a sophisticated form of Recurrent Neural Network (RNN) architecture. The goal of GRU was to address the drawbacks of conventional RNNs, specifically their incapacity to identify long-term dependencies because of problems like vanishing and exploding gradients during time backpropagation.
Why GRU Was Introduced?
- Long sequences are difficult for traditional RNNs to learn patterns over because they lose track of crucial prior knowledge. LSTMs have more parameters and a higher computational complexity, despite the fact that they addressed this with memory cells and intricate gating mechanisms.
- This is made simpler by the GRU, which retains the capacity to discover long-term links in data by removing the memory cell and merging a few gates. It uses two primary gates to accomplish this:
- Update Gate: Regulates the amount of prior memory that is transferred to the present state.
- Reset Gate: Regulates how much of the past should be forgotten.
- LSTM against GRU:
- LSTM: memory cell plus three gates (input, forget, and output).
- GRU: No distinct memory cell plus two gates (update and reset).
Importance in Deep Learning:
GRUs work especially well in fields like natural language processing (NLP), which includes sentiment analysis, translation, and text classification.
- Speech recognition is the processing of temporal audio data.
- Time Series Prediction: Making predictions about the weather, market prices, etc.
Keybenefits,
- Frequently performs as well as LSTM in many applications;
- Requires less parameter than LSTM, which speeds up training.
- Because of their simplicity, they are easier to apply and adjust.
In short, GRUs represent a smart trade-off between performance and efficiency, making them a popular choice in deep learning applications involving sequential or time-dependent data.
Detailed Gated Recurrent Unit (GRU) Algorithm
The Gated Recurrent Unit (GRU) is a variant of RNNs that uses gating mechanisms to control the flow of information, helping the model to retain long-term dependencies and forget irrelevant data. At each time step t, the GRU takes in:
- The current input vector xt
- The previous hidden state ht
It outputs:
- The new hidden state ht
GRU Components,
- Update Gate (zt) – Decides how much of the previous hidden state should be carried forward.
- Reset Gate (rt) – Decides how much of the previous hidden state to forget.
- Candidate Hidden State (h~t) – Proposes a new hidden state.
- Final Hidden State (ht) – The actual output hidden state at time t.
Step-by-Step GRU Algorithm,
Step 1: Compute the Update Gate zt
The update gate determines how much of the past information to pass along to the future.
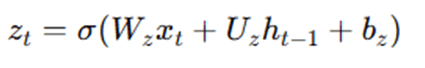
Where, Wz Uz – weight matrices, bz – bias and σ – sigmoid activation function
Step 2: Compute the Reset Gate rt
The reset gate decides how much of the past information to forget.

Where, Wr, Ur – weight matrices and br – bias
Step 3: Compute the Candidate Hidden State h~t
This is a proposal for the new hidden state using the reset gate.
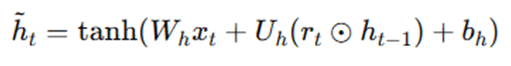
Where, Wh, Uh – weight matrices, bh – bias, ⊙– element-wise multiplication and tanh– hyperbolic tangent activation function. The reset gate rt decides how much of ht−1 to consider when calculating th~t.
Step 4: Compute the Final Hidden State ht
This is a blend of the previous hidden state ht−1 and the new candidate h~t, controlled by the update gate.

Where, (1−zt) decides how much of the previous hidden state to retain and zt decides how much of the new candidate state to use.
GRU Parameter,
| Parameter | Description |
| xt | Input at time step t |
| ht−1 | Hidden state from the previous time step |
| Ht | Current hidden state |
| Zt | Update gate |
| rt | Reset gate |
| h~t | Candidate hidden state |
| W,U,b | Learnable weight matrices and biases |
Conceptual Flow,
- Decide how much past info to forget → Reset gate
- Create a candidate for new memory → h~t
- Decide how much of the candidate to keep → Update gate
- Generate the final memory output → ht
This algorithm is repeated across all time steps in a sequence. GRU’s elegance lies in this simple yet powerful mechanism that enables it to learn from both short and long-term dependencies efficiently.
Advantages and Disadvantages of Gated Recurrent Unit (GRU)
Advantages
- Simpler Architecture than LSTM: GRU has a more compact architecture compared to Long Short-Term Memory (LSTM) networks. It combines the forget and input gates into a single update gate, and merges the cell and hidden states, resulting in fewer parameters and easier training.
- Efficient Training: Due to its simpler structure, GRU generally trains faster and requires less computational power and memory than LSTM. This makes it a practical choice for resource-constrained environments or real-time applications.
- Comparable Performance to LSTM: Despite its simplicity, GRU achieves comparable or even better performance than LSTM on many tasks involving sequential data, such as sentiment analysis, time series forecasting, and machine translation.
- Effective at Capturing Dependencies: GRUs are effective at modeling short- and medium-range temporal dependencies in sequence data. The gating mechanisms help mitigate the vanishing gradient problem that plagues vanilla RNNs.
- Fewer Hyperparameters: With fewer gates and internal states, GRUs are easier to tune compared to LSTM models. This reduces the trial-and-error required during model optimization.
- Works Well with Limited Data: GRUs tend to generalize well with smaller datasets, where the simplicity of the model reduces the risk of overfitting compared to more complex architectures.
Disadvantages
- Not Always Better Than LSTM: Although GRUs perform well in many scenarios, LSTMs may outperform them in tasks requiring learning of very long-term dependencies, such as lengthy paragraphs or video sequences.
- Limited Flexibility: The GRU’s merged gate structure (update and reset gates) is less flexible than LSTM’s separate control of memory flow, which may limit its ability to learn fine-grained patterns in certain datasets.
- Still Computationally Intensive Compared to Simpler Models: While more efficient than LSTM, GRUs are still heavier than basic RNNs and may not be ideal for extremely low-resource devices or ultra-fast real-time systems.
- Not Universally Optimal: There’s no universal rule that GRU is better than LSTM or vice versa — performance is task-dependent. Choosing GRU over LSTM often requires empirical testing for your specific application.
- Opaque Inner Workings: Like most deep learning models, GRUs are difficult to interpret, which can be a disadvantage in sensitive applications (e.g., healthcare or finance) where model transparency is important.
| Aspect | Advantages | Disadvantages |
| Architecture Simplicity | Fewer parameters and simpler design than LSTM | Less flexible in handling long-term memory |
| Training Speed | Faster and more efficient to train | Still slower than non-recurrent models like transformers |
| Performance | Comparable or superior to LSTM on many tasks | May underperform on very long sequences |
| Suitability for Small Data | Performs well with limited training data | May overfit on complex tasks if not tuned carefully |
| Interpretability | Fewer components to analyze | Still a “black-box” model with limited interpretability |
Applications of Gated Recurrent Unit (GRU) Algorithm
- Natural Language Processing (NLP): GRUs are widely used in natural language processing tasks due to their ability to handle sequential data effectively. In machine translation, GRUs power sequence-to-sequence (Seq2Seq) models that translate text from one language to another. They’re also used in text classification, sentiment analysis, and named entity recognition, where understanding context and word order is crucial. Their efficiency and comparable performance to LSTMs make GRUs a go-to model for real-time NLP applications such as chatbots and voice assistants.
- Time Series Forecasting: In domains like finance, weather prediction, and stock market analysis, GRUs are applied to forecast future values in time series data. They learn temporal dependencies and trends in the data without the need for extensive preprocessing. GRUs are particularly valuable when datasets are noisy or irregularly spaced, as their gating mechanisms help capture both short- and long-term patterns.
- Anomaly Detection in Sequences: GRUs are used in anomaly detection systems, especially where data is time-dependent, such as in network traffic monitoring, industrial sensors, and smart grid systems. By learning the normal patterns in sequential data, GRU-based models can flag deviations that indicate faults, cyberattacks, or equipment failure.
- Speech Recognition and Audio Processing: In speech-to-text systems, GRUs help model temporal audio signals and transcribe spoken language with impressive accuracy. They are also employed in voice activity detection, speaker identification, and music genre classification, where the time evolution of audio features is critical.
- Healthcare and Biomedical Signal Analysis: GRUs are applied to biomedical sequence data, such as ECG, EEG, and patient monitoring systems. For example, they can help detect cardiac arrhythmias or predict epileptic seizures by learning from time-stamped physiological data. Their ability to work with limited data and noise makes them well-suited for medical environments.
- Video Frame Prediction and Action Recognition: GRUs can be used to model sequences of video frames in video analysis tasks such as action recognition, frame prediction, or video captioning. They track the evolution of visual features over time, helping AI understand and predict motion in a scene.
- Robotics and Control Systems: In robotics, GRUs contribute to trajectory prediction, navigation, and control systems, where sequential sensor readings guide real-time decision-making. They help robots adapt to dynamic environments by modeling patterns in continuous input streams like camera feeds or inertial data.
- Recommendation Systems: GRU-based recurrent recommendation models can capture the sequential behavior of users — for example, predicting what a user will click or purchase next based on their recent browsing or interaction history. This is particularly effective in e-commerce and content platforms where user behavior is highly temporal.
- Financial Modeling and Algorithmic Trading: GRUs are employed in forecasting stock prices, predicting market trends, and automating trading strategies. Their strength in modeling time-dependent data makes them suitable for handling complex, non-linear relationships in financial time series.
- IoT and Sensor Data Analysis: In Internet of Things (IoT) applications, GRUs process streams of sensor data from devices such as wearables, smart meters, and industrial machines. Tasks include predictive maintenance, fault detection, and real-time monitoring — all of which require robust sequence modeling.
Conclusion
An important development in deep learning, especially for jobs using sequential data, is the Gated Recurrent Unit (GRU) method. GRUs provide a workable solution to the drawbacks of conventional RNNs by implementing a straightforward yet efficient gating mechanism, particularly when managing long-term dependencies and addressing the vanishing gradient issue. They are ideal for real-time and resource-constrained applications because of their architecture, which balances computational efficiency and performance with just two gates: the update and reset gates. Natural language processing, speech recognition, time series forecasting, and anomaly detection are just a few of the fields in which GRUs have demonstrated their efficacy. They can represent intricate temporal correlations in data with remarkable precision because of their capacity to adaptively learn which information to remember and which to forget. In conclusion, the GRU algorithm is a crucial part of the arsenal of contemporary machine learning researchers and practitioners who work with sequential data because it blends simplicity, speed, and powerful learning capabilities.
Frequently Asked Questions (FAQs)
Q1: What is the main difference between GRU and LSTM?
Answer: Their architecture is where they diverge most. Whereas LSTM has three gates—input, forget, and output—as well as a distinct memory cell, GRU only has two gates—update and reset. LSTMs may outperform GRUs on extremely complicated sequences, although GRUs are simpler and frequently train faster.
Q2: Why should I use GRU instead of a traditional RNN?
Answer: Compared to conventional RNNs, GRUs are better suited to managing long-term dependencies. They improve performance on jobs involving lengthy sequences and assist in resolving problems such as the vanishing gradient problem.
Q3: Are GRUs suitable for real-time applications?
Answer: Yes, because of their simplified structure, GRUs are computationally economical, which makes them perfect for real-time tasks like anomaly detection, online translation, and speech recognition.
Q4: Can GRUs be used for time series forecasting?
Answer: Of course. Because GRUs can capture temporal patterns and trends across time, they are frequently employed for time series forecasting applications, such as energy usage, weather prediction, and stock price forecasting.
Q5: Do GRUs always outperform LSTMs?
Answer: Not all the time. LSTMs can occasionally outperform GRUs on lengthy or extremely complex sequences, despite GRUs being quicker and simpler. The particular dataset and situation often determine which of GRU and LSTM is best.









