
What is Deep Q-Networks (DQN) Algorithm?
The Deep Q-Network (DQN) algorithm is a reinforcement learning technique that solves issues with very large or continuous state or action spaces by combining Q-learning with deep neural networks. In order to approximate the Q-value function Q(s,a) which predicts the expected cumulative reward of taking an action an in a given state s and then following the optimal policy thereafter, DQN uses a deep neural network rather than maintaining a Q-table, which becomes impractical in high-dimensional spaces. Key ideas that make DQN powerful:
- Neural Network Approximation: Using a state as input, a neural network generates Q-values for every action that could be taken.
- Experience Replay: To break the correlation between successive experiences, DQN randomly selects samples from a replay buffer that contains experiences (state, action, reward, and future state).
- Target Network: To provide more stable training, target Q-values are calculated using a second, slower-updated network.
In short, DQN allows agents to learn directly from high-dimensional sensory inputs (like images) and still perform complex decision-making tasks effectively.
Introduction of DQN Algorithm
Training agents to make a series of decisions by interacting with their surroundings in order to maximize cumulative rewards is known as reinforcement learning, or RL. Because it is hard to keep or update every state-action pair in a table, traditional techniques like Q-learning perform poorly in environments with huge or continuous state spaces. To get around this restriction, DeepMind launched Deep Q-Networks (DQN) in 2015. DQN uses deep neural networks in conjunction with Q-learning to approximate the Q-function Q(s,a) rather than relying on a lookup table. This enables agents to learn complicated behaviors from high-dimensional, raw data, such as gaming video frames.
DQN’s two main innovations are:
- Experience Replay: To reduce correlations and increase stability, historical experiences are randomly selected and stored for training.
- Target Networks: To stabilize the training process, a different, gradually updated network is used to provide the target Q-values throughout learning.
By using these methods, DQN was able to play Atari 2600 video games at a level comparable to that of humans, which was a significant advancement in deep reinforcement learning and artificial intelligence.
Detailed DQN Algorithm
The goal of DQN is to learn the optimal Q-function Q∗(s,a), which gives the expected return (total future reward) for taking an action a in state s, and then following the best policy.
Step 1: Initialize Components
- Initialize a Q-network with random weights θ. This network approximates Q(s,a;θ).
- Initialize a target Q-network with weights θ−=θ. This is a fixed copy used to calculate target values.
- Initialize an experience replay buffer D with capacity N.
Step 2: Interaction with the Environment (Collecting Experience)
For each episode:
- Start in an initial state s0.
- For each time step t:
- Choose an action at using an ε-greedy policy:

- Execute action at, receive reward rt, and observe next state st+1.
- Store the transition (st,at,rt,st+1) in the replay buffer D.
Step 3: Sampling from Experience Replay
- Randomly sample a minibatch of transitions (s,a,r,s′) from D.
Step 4: Compute Target Q-values
For each transition in the minibatch:
- If s′ is a terminal state:
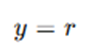
- Otherwise:
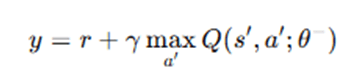
Where:
- y is the target Q-value.
- γ∈[0,1] is the discount factor.
Step 5: Compute Loss and Update Q-network
- Define the loss function (Mean Squared Error between target and predicted Q-values):
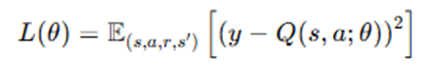
- Perform a gradient descent step to minimize the loss and update θ.
Step 6: Update Target Network
Every fixed number of steps C, update the target network:

Summary of the DQN Training Loop

Key Concepts,
- ε-greedy: Balances exploration and exploitation.
- Experience Replay: Breaks correlation between samples.
- Target Network: Stabilizes learning by keeping targets fixed temporarily.
- Gradient Descent: Updates network weights to reduce prediction error.
Advantages and Disadvantages of DQN Algorithm
Advantages
- Handles High-Dimensional Input (e.g., Images): DQNs use deep neural networks to approximate Q-values, making them capable of handling large and complex state spaces like raw pixel inputs from video games (e.g., Atari).
- Experience Replay: By storing and randomly sampling past experiences, DQNs break the correlation between sequential data points, improving learning stability and efficiency.
- Target Network Stabilization: The use of a separate target network (with delayed updates) helps stabilize learning by reducing oscillations and divergence.
- Generalization Capability: Due to the use of deep neural networks, DQNs can generalize over unseen states more effectively than traditional tabular Q-learning.
- Demonstrated Success in Complex Tasks: DQN achieved human-level performance on many Atari 2600 games, showcasing its effectiveness in complex, high-dimensional environments.
- Model-Free Learning: DQN does not require a model of the environment, making it suitable for real-world scenarios where models are hard to construct.
Disadvantages
- Sample Inefficiency: DQN typically requires a large number of interactions with the environment to learn an effective policy.
- Instability and Sensitivity to Hyperparameters: Training can be unstable and highly sensitive to learning rate, discount factor, replay buffer size, etc.
- Limited to Discrete Action Spaces: The standard DQN algorithm only works with discrete action spaces. It is not directly applicable to continuous action domains.
- Delayed Convergence: DQNs may take a long time to converge to an optimal policy, especially in environments with sparse rewards or delayed feedback.
- Overestimation Bias: DQNs tend to overestimate Q-values due to the max operator in the Bellman equation. This has led to variants like Double DQN to address this issue.
- Computational Resources: Deep neural networks require significant computational resources (e.g., GPU), especially for environments with high-dimensional input.
Applications of Deep Q-Networks Algorithm
- Game Playing: One of the most celebrated applications of Deep Q-Networks (DQN) is in the domain of game playing. DQN was famously used by DeepMind to play Atari 2600 games, where it achieved human-level or even superhuman performance in games such as Breakout, Pong, and Space Invaders. The algorithm can handle pixel-based input and learns directly from gameplay using reward signals, making it highly suitable for reinforcement learning benchmarks and a variety of board and video games.
- Autonomous Vehicles: DQN is applied in autonomous driving to support critical decision-making processes such as lane changing, obstacle avoidance, and path planning. Simulated driving environments like the CARLA simulator have successfully employed DQN to teach self-driving cars how to navigate safely without the need for manually crafted control models. Its ability to learn optimal driving actions makes it ideal for real-time, complex vehicular scenarios.
- Robotics: In robotics, DQN is utilized for tasks like robotic arm manipulation, object handling, and navigation in dynamic environments. For example, DQN has been applied to help robots learn how to pick and place objects using camera input. The algorithm excels in learning policies in high-dimensional sensor-based state spaces, making it valuable for physical task execution and adaptive behaviors in robots.
- Smart City and Traffic Signal Control: DQN plays a significant role in smart city infrastructure, particularly in traffic signal control. By analyzing real-time traffic patterns, DQN decides optimal switching times for traffic lights to reduce congestion and waiting time. It effectively manages complex, dynamic systems and delayed reward scenarios, offering more adaptive and efficient traffic management solutions.
- Recommender Systems: DQN is used in recommender systems to personalize content or product suggestions based on user interaction patterns. Instead of relying on static, one-shot predictions, DQN models user engagement over time and balances exploration and exploitation strategies. This approach leads to more intelligent and dynamic recommendation engines that consider long-term user satisfaction.
- Wireless Communication and Networking: In wireless networks, DQN helps with dynamic spectrum allocation, packet routing, and load balancing. It is especially useful in next-generation systems like 5G, where it optimizes throughput and minimizes latency. By adapting to changing network conditions, DQN learns effective strategies for resource allocation, improving overall communication efficiency.
- Energy Management Systems: DQN has promising applications in smart grid and energy systems. It is used to manage dynamic pricing, schedule loads, and optimize appliance operations. For instance, DQN can determine the best times to run household appliances to reduce peak load and electricity costs. Its strength lies in handling non-linear reward structures and achieving long-term energy efficiency.
- Healthcare and Medical Decision Support: In healthcare, DQN supports medical decision-making through personalized treatment planning and dosage control. A notable example includes using DQN in simulated environments to optimize insulin dosage for diabetic patients. The algorithm deals effectively with uncertainty and sequential decision-making, making it suitable for complex, patient-specific care strategies.
- Finance and Trading: DQN is employed in financial markets to develop stock trading strategies and optimize investment portfolios. It learns when to buy, hold, or sell assets based on market indicators to maximize cumulative returns. By learning from temporal patterns and delayed feedback, DQN becomes a powerful tool for algorithmic trading and financial forecasting.
- Simulated Training and AI Agents: Finally, DQN is extensively used to train virtual agents in simulations, games, and interactive virtual environments. For example, it is used to teach non-playable characters (NPCs) behaviors or to develop AI teammates in cooperative or competitive games. The algorithm supports learning from ongoing interaction rather than relying on predefined rules or scripting, allowing more human-like behavior development in digital environments.
Conclusion
The Deep Q-Network (DQN) algorithm successfully combines Q-learning with deep neural networks, marking a significant breakthrough in the field of reinforcement learning. It overcomes the difficulties presented by continuous and high-dimensional state spaces, enabling agents to learn straight from unprocessed inputs without the need for manually created features. DQN stabilizes the training process and makes effective, scalable learning possible by bringing important advances like experience replay and target networks. Its exceptional performance on challenging tasks, such playing Atari games at superhuman levels, revealed the potent potential of deep reinforcement learning and led to new lines of inquiry. DQN’s fundamental concepts have served as the basis for numerous sophisticated algorithms, despite certain drawbacks, such as its sensitivity to hyperparameters and difficulty in continuous action spaces. All things considered, DQN is a significant turning point that keeps influencing the development of increasingly complex reinforcement learning techniques in both scholarly research and real-world applications.
Frequently Asked Questions (FAQs)
Q1: What is the main idea behind DQN?
Answer: DQN’s primary concept is to approximate the Q-value function using a deep neural network, which allows an agent to make decisions in situations where standard Q-learning would not be practical due to extremely huge or complex state spaces.
Q2: Why is experience replay important in DQN?
Answer: Experience replay is essential because it randomly selects prior events for training, which helps break the strong correlations between successive encounters. This enhances overall performance, stabilizes learning, and improves data efficiency.
Q3: What role does the target network play in DQN?
Answer: By holding its parameters constant for a predetermined number of steps prior to updating, the target network offers learning targets that are stable. This makes training more stable by lowering the possibility of feedback loops in which the network continuously pursues its own moving predictions.
Q4: How does DQN differ from traditional Q-learning?
Answer: DQN employs a deep neural network to generalize Q-value predictions across broad or continuous state spaces, which makes it appropriate for complicated real-world situations, whereas classical Q-learning uses a straightforward table to store Q-values for each state-action pair.
Q5: What are some limitations of the DQN algorithm?
Answer: Notwithstanding its advantages, DQN has drawbacks, such as its susceptibility to hyperparameters such as learning and exploration rates, its incapacity to manage continuous action spaces, and the possibility of instability during training in the event that experience replay or target networks are not appropriately adjusted.









